
A 147-person feasibility randomized trial found that both a structured AI therapy chatbot and general ChatGPT reduced PHQ-9 depression scores compared with assessment-only control, with effect sizes of d = −0.47 and d = −0.44.1 The purpose-built therapy bot did not significantly outperform ChatGPT on depression, anxiety, impairment, or wellbeing.
Research Highlights
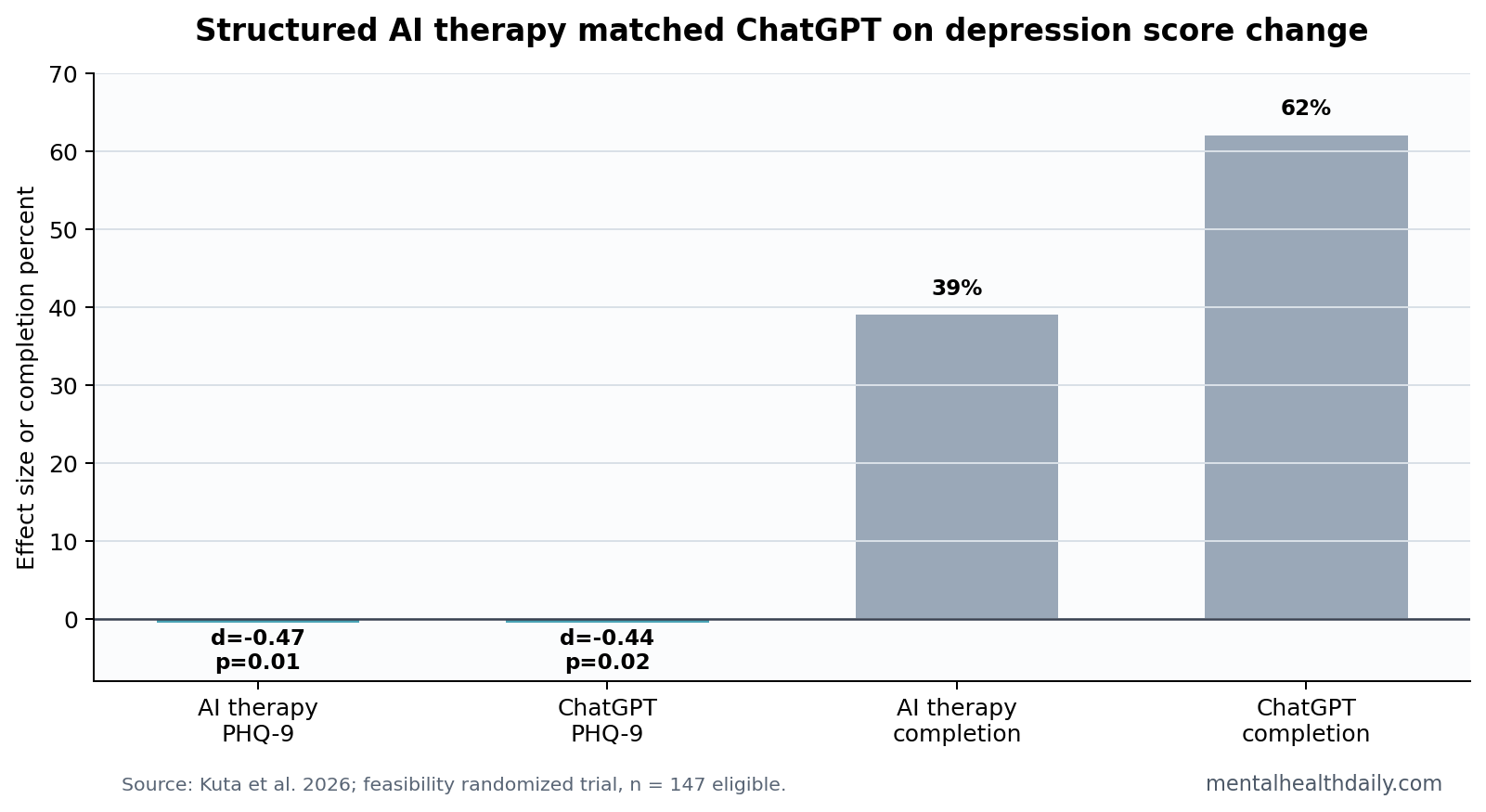
- Both chatbots reduced PHQ-9 scores: AI therapy had d = −0.47, p = 0.01, and ChatGPT had d = −0.44, p = 0.02, compared with assessment-only control.1
- Structured therapy did not beat ChatGPT: AI therapy vs. ChatGPT was nonsignificant for PHQ-9, GAD-7, ODSIS, and WHO-5, with PHQ-9 p = 0.87.1
- Completion favored ChatGPT: 39% of AI therapy participants completed all sessions vs. 62% of ChatGPT participants.1
- Clinical size was modest: mean PHQ-9 changes of about 2.7 and 2.5 points did not meet the paper’s cited minimal clinically important difference.1
- Prior chatbot evidence is mixed: meta-analyses show short-course symptom reductions, but attrition and weak comparators remain recurring limits.2
Generative AI therapy chatbots use large language models to produce personalized text or voice responses, often wrapped in a structured therapeutic script. The clinical question is whether structure adds more than ordinary supportive conversation with a general model.
Kuta et al. tested that question directly. Participants were assigned to a mobile AI therapy program, general ChatGPT conversations, or assessment-only control over 3 weeks. The intended dose was 9 sessions.1
PHQ-9 Depression Scores Improved in Both Chatbot Groups
The strongest outcome was depression on the PHQ-9, a 9-item self-report measure of depressive symptom severity. AI therapy reduced PHQ-9 scores by 2.67 points more than control, d = −0.47, p = 0.01. ChatGPT reduced PHQ-9 scores by 2.47 points more than control, d = −0.44, p = 0.02.1
Those are meaningful short-term signals, especially because both active groups beat assessment-only control. They are not proof of clinical replacement. The paper itself noted that the mean PHQ-9 changes did not reach the cited minimal clinically important difference.
The Purpose-Built Therapy Bot Did Not Outperform ChatGPT
The central calibration is the head-to-head result. AI therapy did not significantly outperform ChatGPT on PHQ-9, GAD-7 anxiety, ODSIS depression impairment, or WHO-5 wellbeing.1
That result cuts against the assumption that therapeutic packaging automatically creates a better mental-health intervention. A structured program may improve safety, consistency, and auditability. It did not produce superior outcomes in this short feasibility test.
Completion also complicates the interpretation. Only 17 AI therapy participants completed all sessions, 39%, compared with 38 ChatGPT participants, 62%. If a structured program is harder to finish, its theoretical advantages may not reach users.
Conversational-Agent Evidence Needs Active Comparators
Prior reviews of conversational agents have found improvements in depression and anxiety symptoms, but the evidence often depends on short trials, waitlist controls, and heterogeneous tools.2 AI-based conversational-agent reviews reach a similar cautious conclusion: promising, not settled.3
The Kuta trial improves the question by adding a general ChatGPT arm. That makes the result more useful than a simple chatbot vs. waitlist comparison. The trial still lacks a human-care comparator, longer follow-up, and objective safety monitoring.
Dose also changes the interpretation. Both active groups were asked to complete 9 sessions or conversations across 3 weeks, but completion separated sharply: 17 AI therapy users completed the full program vs. 38 ChatGPT users.1 A therapy-specific design can look stronger on paper while losing users during ordinary use. In a low-intensity digital intervention, adherence is not a side endpoint; it is part of the treatment mechanism.
Evidence-strength note: this was a feasibility RCT with online self-report outcomes over 3 weeks. It supports short-term symptom calibration, not claims about diagnosis, crisis care, medication decisions, or replacement of clinicians.
Practical Use Should Separate Support From Treatment
For readers, the safest interpretation is that chatbot contact may offer short-term support for some depressive symptoms, but treatment claims require a higher bar. The system must define what it can do, what it cannot do, when it escalates risk, and how adverse responses are audited.
- Reasonable use: mood tracking, brief reflection, behavioral prompts, and low-risk support between ordinary care contacts.
- Unsafe use: crisis triage, diagnosis, medication guidance, or replacing needed professional care.
- Research priority: compare structured bots with general models, human-guided digital care, and credible active controls.
The Control Group Was Assessment-Only, Not Human Care
The trial’s control group received assessment only. That matters because a chatbot can beat no active support and still fail against therapist-guided digital care, structured self-help, or ordinary psychotherapy. The effect size answers one question: did chatbot access outperform measurement alone over 3 weeks?
It does not answer whether a chatbot is better than a low-cost human coach, a workbook with reminders, group CBT, a crisis line, medication management, or usual care. Those are the comparisons that decide clinical and health-system value.
Active comparator means the control condition offers a credible intervention rather than only waiting or repeated measurement. AI mental-health trials need active comparators because attention, novelty, expectation, and repeated self-reflection can all reduce symptoms.
Assessment-only control is still useful for feasibility because it shows whether the trial can recruit, randomize, retain, and measure participants without human delivery. It is weaker for clinical ranking. A low-cost tool can look promising against no active support, then lose its advantage when compared with guided internet CBT, a coached app, brief human check-ins, or another chatbot that delivers similar attention with fewer constraints.
Completion Rates Change the Product Claim
The structured AI therapy program had lower completion than ChatGPT, 39% vs. 62%.1 That adherence statistic changes how to read the product claim.
A therapy-specific bot may be safer and more consistent because it constrains the interaction. But constraint can also make the experience less flexible, less engaging, or less responsive to what the user wants to discuss. General ChatGPT may have kept more people because it allowed looser conversation.
That tradeoff is central to AI mental-health design. More structure may improve guardrails and fidelity. Less structure may improve user fit and completion. A useful product has to solve both problems at the same time: people need to stay engaged, and the system needs to avoid unsafe or low-quality responses.
Safety Cannot Be Inferred From Symptom Improvement
A short-term PHQ-9 reduction does not prove that a chatbot handles risk well. Depression trials can include people with low acute risk, exclude severe presentations, or miss adverse interactions that appear only at larger scale.
Safety evaluation should include crisis detection, escalation behavior, hallucinated advice, inappropriate reassurance, privacy handling, and the system’s response to dependency or repeated distress. Those endpoints are not captured by a simple pre-post symptom score.
That does not make the Kuta trial unimportant. It makes the trial appropriately narrow. It shows that short chatbot access can reduce self-reported depression scores compared with assessment only. The next evidentiary step is to test whether those benefits survive stronger comparators and safety audits.
PHQ-9 Change Needs Clinical Calibration
PHQ-9 is useful because it is brief, widely used, and sensitive to depressive-symptom change. A few points can still mean different things depending on baseline severity, impairment, suicidality, and whether the change persists.
Kuta et al. reported mean PHQ-9 changes of about 2.7 points for AI therapy and 2.5 points for ChatGPT compared with control.1 Those changes were statistically significant but below the cited minimal clinically important difference. In plain terms, the trial found a real short-term scale movement, not a clear clinical-response claim.
That calibration matters because AI therapy marketing often jumps from “statistically significant” to “clinically meaningful.” The difference is not pedantic. A statistically significant 2.5-point change may be useful for low-intensity support, but it is not the same as remission, functional recovery, or reduced need for human care.
A stronger trial would report response, remission, deterioration, adverse events, crisis escalations, and sustained follow-up. Symptom improvement should be paired with a harm audit, especially when the intervention can generate persuasive personalized language. Benefit without safety context is incomplete evidence.
The same standard should apply to ordinary ChatGPT comparisons. General models may feel more natural because they are flexible, but flexibility can also produce inconsistent boundaries, unsupported reassurance, or advice that drifts away from the user’s risk level. Structured bots and general models therefore need the same audit frame: symptom change, engagement, safety behavior, and escalation quality measured together.
For now, the best reading is narrow but useful: chatbot access produced short-term depression-score movement, and the custom therapy wrapper did not add a measurable advantage over general ChatGPT in this sample. That is enough to justify larger trials, not enough to justify replacing established care.
Questions About AI Therapy Chatbots
Did ChatGPT work as well as the therapy chatbot?
In this trial, yes on measured outcomes. Both reduced PHQ-9 scores vs. control, and the therapy chatbot did not significantly outperform ChatGPT.
Was anxiety reduced?
AI therapy showed a nonsignificant anxiety trend, d = −0.37. ChatGPT showed a smaller nonsignificant anxiety trend, d = −0.12.
Does this prove AI therapy is safe?
No. Short-term symptom scores cannot establish crisis safety, diagnostic reliability, or quality control across broad real-world use.
References
- Kuta B, et al. Effectiveness of a fully automated mobile therapeutic versus a general chatbot in reducing depression and anxiety and improving well-being: feasibility randomized controlled trial. JMIR Mental Health. 2026;13:e82642. https://doi.org/10.2196/82642
- He Y, et al. Conversational agent interventions for mental health problems: systematic review and meta-analysis of randomized controlled trials. Journal of Medical Internet Research. 2023;25:e43862. https://doi.org/10.2196/43862
- Li H, et al. Systematic review and meta-analysis of AI-based conversational agents for promoting mental health and well-being. NPJ Digital Medicine. 2023;6:236. https://doi.org/10.1038/s41746-023-00979-5
- Jabir AI, et al. Attrition in conversational agent-delivered mental health interventions: systematic review and meta-analysis. Journal of Medical Internet Research. 2024;26:e48168. https://doi.org/10.2196/48168