
A 2026 ABCD Study preprint found that teen substance-use initiation prediction improved more when models included changing risk over time than when they simply switched from logistic regression to multi-task learning.1 Dynamic models raised AUROC by 0.044 to 0.062 in multi-task learning and by 0.050 to 0.084 in logistic regression, which makes timing the main signal rather than model complexity alone.
Research Highlights
- Longitudinal timing carried the biggest gain: Dynamic modeling improved AUROC by +0.044 to +0.062 for multi-task models across alcohol, nicotine, cannabis, and any-substance initiation.1
- Multi-task learning helped most when events were rare: Static multi-task learning improved AUROC by +0.039 for cannabis and +0.030 for nicotine compared with single-task logistic regression, while alcohol and any-substance gains were small.1
- The cohort was large but the rare outcomes stayed thin: The analysis retained 11,187 ABCD participants, yet held-out cannabis initiation involved 37 events and nicotine initiation involved 67 events.1
- Shared predictors were narrow: Externalizing behavior, parental monitoring, and developmental factors recurred across model types, while many other predictors were model-specific.1
- This is prediction, not prevention proof: The 2026 preprint can rank risk and compare modeling strategies, but it cannot show that changing a flagged family, behavioral, or genetic variable prevents teen substance use.
Substance-use initiation prediction means estimating which adolescents are more likely to start using alcohol, nicotine, cannabis, or any substance during follow-up. In this analysis, the outcome was not addiction diagnosis or treatment response; it was first reported initiation during the ABCD Study’s longitudinal follow-up.1
Multi-task learning is a machine-learning setup that trains related outcomes together. Instead of fitting one isolated model for alcohol, another for nicotine, another for cannabis, and another for any substance use, a shared model can learn patterns that carry across substances while still allowing outcome-specific predictions.
Dynamic prediction means the model uses time-varying information rather than only baseline measures. For teen substance use, that distinction is concrete: family monitoring, peer context, externalizing behavior, sleep, puberty, mental-health symptoms, and access to substances can change during adolescence, so a baseline-only risk score may miss the timing of exposure.
Dynamic Models Beat Baseline-Only Risk Scores
Wei et al. analyzed ABCD release 5.1, a large U.S. longitudinal cohort that enrolled children at age 9 to 10 years and follows them into adolescence. The split-eligible cohort included 11,868 participants with mean baseline age 9.91 years. Substance-use initiation by follow-up was common for alcohol and any substance, but much rarer for nicotine and cannabis:
- Alcohol initiation: 4,330 of 11,868 participants, or 36.5%.
- Any substance initiation: 4,706 of 11,868 participants, or 39.7%.
- Nicotine initiation: 646 of 11,868 participants, or 5.44%.
- Cannabis initiation: 406 of 11,868 participants, or 3.42%.
The researchers compared 2 prediction strategies. The baseline model used one early record per participant to predict 48-month initiation. The dynamic model converted follow-up into intervals, estimated interval-level initiation risk, and then aggregated those interval probabilities into a subject-level cumulative risk estimate.1
AUROC, or area under the receiver operating characteristic curve, measures how well a model separates people who do and do not have the outcome. A value of 0.50 is chance-level discrimination, while 1.00 is perfect separation. PR-AUC, or area under the precision-recall curve, is especially useful when events are rare because it focuses more directly on positive-case identification.
Dynamic modeling improved AUROC across every tested outcome. In multi-task learning, the AUROC gain ranged from +0.044 for nicotine to +0.062 for any-substance initiation. In logistic regression, the gain ranged from +0.050 for alcohol to +0.084 for cannabis.1
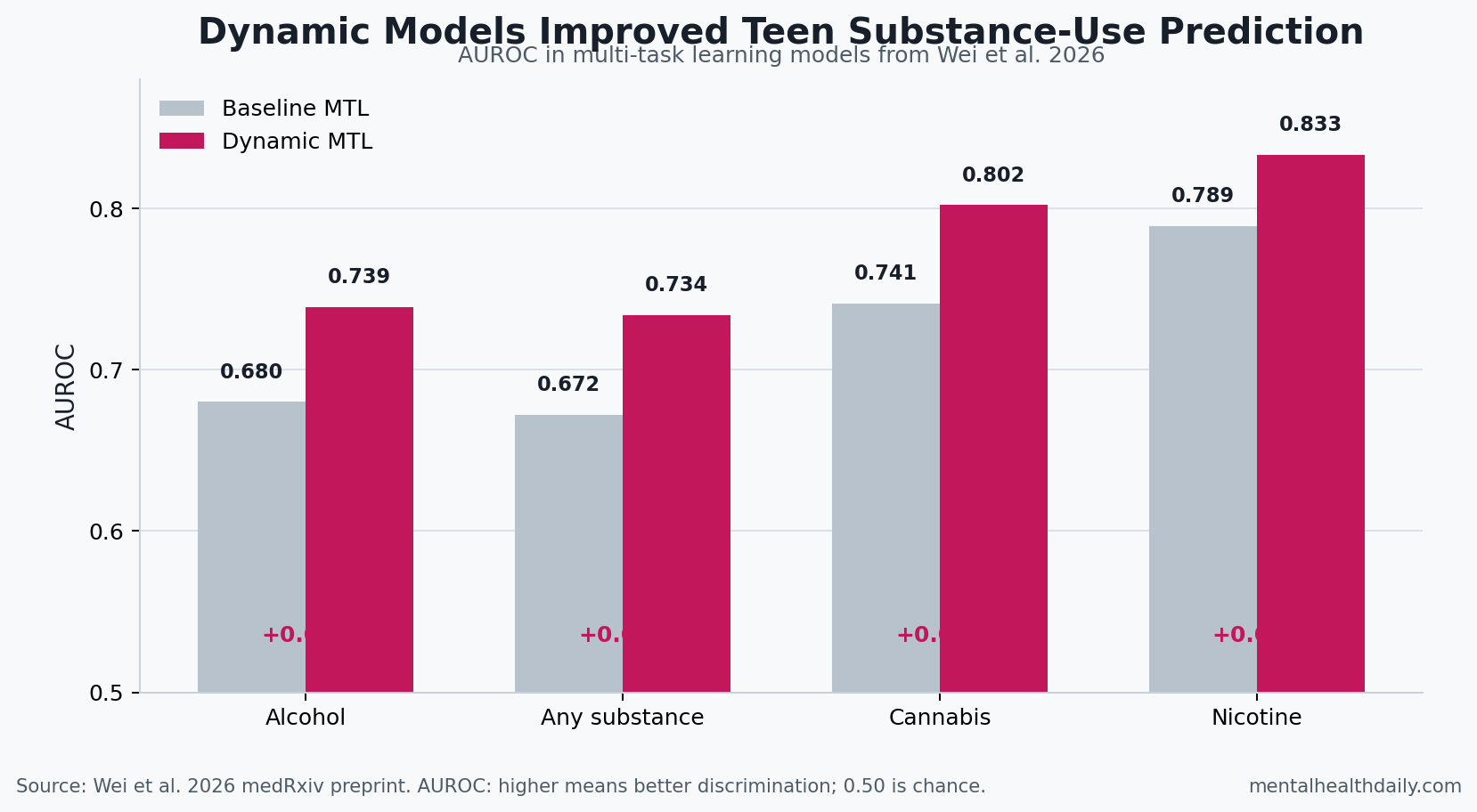
Multi-Task Learning Helped Most for Rare Outcomes
Multi-task learning was not useless. The sharper calibration is that it helped selectively, especially when initiation events were sparse.
In the static baseline setting, multi-task learning barely changed alcohol AUROC compared with logistic regression: 0.680 vs. 0.682. Any-substance AUROC was also essentially unchanged: 0.672 vs. 0.671. The rare outcomes looked different. Cannabis AUROC rose from 0.702 with logistic regression to 0.741 with multi-task learning, and nicotine AUROC rose from 0.759 to 0.789.1
The likely reason is information sharing: when cannabis or nicotine initiation has fewer positive cases, a model that learns shared structure across related substance outcomes may stabilize the signal. That does not make the shared model automatically better for every endpoint. Common outcomes already gave single-task logistic regression enough signal to perform similarly.
Dynamic models kept the same pattern but narrowed the gap. Dynamic multi-task learning beat dynamic logistic regression for alcohol, any substance, and cannabis, while dynamic logistic regression slightly exceeded multi-task learning for nicotine AUROC: 0.837 vs. 0.833. PR-AUC still favored dynamic multi-task learning for nicotine by +0.042.1
Externalizing Behavior and Parental Monitoring Were the Stable Signals
Feature-importance results were more cautious than the performance results. Feature importance means estimating which inputs most changed model performance or ranking, not proving that the input causes the outcome.
Across static multi-task learning, dynamic multi-task learning, and Cox time-to-event models, only a small set of features kept reappearing. Alcohol and any-substance initiation repeatedly involved parental monitoring, externalizing or rule-breaking behavior, sensation seeking, pubertal status, parental stress, and family-income context. Cannabis had a narrower reproducible core, with rule-breaking behavior standing out under strict overlap criteria. Nicotine included rule-breaking behavior, nicotine polygenic risk, internalizing symptoms, pubertal status, and sensation seeking.1
Polygenic risk scores estimate inherited liability by summing many genetic variants, each with tiny effects, into a single score. In this paper, polygenic scores were one input family among many. They did not turn the model into a genetic test, and the stronger reader-facing result was that behavioral, family, developmental, and environmental variables remained central.
The findings line up with adjacent evidence rather than appearing from nowhere. Green et al. reported early-adolescent substance-use initiation predictors in the same broad developmental window, while older work linked early alcohol, cigarette, and marijuana patterns to later substance-use outcomes.2,3 Large-scale genetic work has also supported shared liability across self-regulation and addiction-related traits, which fits the paper’s decision to model related substance outcomes together.4
Prediction Models Should Not Be Read as Prevention Trials
This preprint is useful because it separates 2 questions that often get blurred: whether the model architecture helps, and whether the model uses the right time structure. The answer was directional. Shared multi-task learning helped some outcomes, but longitudinal information helped every outcome more consistently.
Clinical and school-based interpretation needs a stricter line. A prediction model can say that risk is higher when certain features cluster before initiation. It cannot prove that changing one selected feature will lower initiation risk, because the analysis was observational and model-based. Parental monitoring, externalizing symptoms, developmental stage, family stress, and genetic liability are also intertwined rather than cleanly randomized inputs.
Evidence-strength note: this was a medRxiv preprint, not a peer-reviewed clinical tool. The model was tested in a held-out ABCD split, but rare events still limited positive-case counts for cannabis and nicotine. The practical use is method calibration: dynamic longitudinal risk modeling looks more informative than a one-time baseline score.
What This Means for Teen Substance-Use Screening
For adolescent substance-use screening, the paper argues against a static “risk profile” mindset. Risk changes as children move through puberty, peer exposure, school transitions, family monitoring changes, sleep disruption, mental-health symptoms, and early experimentation.
A practical screening system built from this logic would need 3 guardrails:
- Repeated measurement: a baseline risk score should be updated as exposures change, especially during the transition from early to middle adolescence.
- Outcome-specific calibration: alcohol, nicotine, and cannabis should not be treated as interchangeable just because some risk factors overlap.
- Human-use limits: model output should support triage, conversation, and follow-up intensity, not label a child as destined for substance use.
Teen substance-use risk is partly shared across substances, but the timing of exposure carries major predictive information. A baseline-only model can miss that moving target, while repeated measurement can keep screening closer to the adolescent’s current risk environment.
Questions About Teen Substance-Use Prediction
Did dynamic multi-task learning accurately predict which teens would start using substances?
It predicted initiation better than baseline-only models, with performance still short of a standalone clinical decision rule. Dynamic multi-task AUROC values were 0.739 for alcohol, 0.734 for any substance, 0.802 for cannabis, and 0.833 for nicotine.1
Those values suggest moderate to strong discrimination, especially for nicotine and cannabis, but the rare-outcome PR-AUC values show that positive-case prediction remains harder than AUROC alone makes it look.
Was multi-task learning better than logistic regression?
Sometimes. Static multi-task learning had its clearest gains for cannabis and nicotine, the lower-prevalence outcomes. For alcohol and any-substance initiation, static multi-task learning was similar to logistic regression.
Adding longitudinal timing improved both model families. That is the stronger design lesson from the preprint.
Can this model prove what causes teen substance use?
No. The analysis can identify predictors and compare prediction strategies, but it cannot assign causal responsibility the way a randomized intervention trial could.
The paper’s feature-importance results should be read as risk-mapping evidence. They help name recurring predictors, but they do not prove that changing any single predictor will prevent alcohol, nicotine, or cannabis initiation.
What should parents or clinicians take from it?
The practical takeaway is repeated assessment. One baseline snapshot is weaker than tracking how behavior, family monitoring, developmental stage, peer context, and mental-health symptoms change over time.
For real-world screening, dynamic risk should trigger better follow-up and more specific questions, not fatalistic labels.
References
- Dynamic and Baseline Multi-Task Learning for Predicting Substance Use Initiation in the ABCD Study. Wei M, Zhang H, Peng Q. medRxiv. 2026. doi:10.64898/2026.04.10.26350655
- Predictors of substance use initiation by early adolescence. Green R, Wolf BJ, Chen A, Kirkland AE, Ferguson PL, Browning BD, Bryant BE, Tomko RL, Gray KM, Mewton L, et al. American Journal of Psychiatry. 2024;181(5):423-433. PubMed
- Early adolescent patterns of alcohol, cigarettes, and marijuana polysubstance use and young adult substance use outcomes in a nationally representative sample. Moss HB, Chen CM, Yi HY. Drug and Alcohol Dependence. 2014;136:51-62. PubMed
- Multivariate analysis of 1.5 million people identifies genetic associations with traits related to self-regulation and addiction. Karlsson Linner R, Mallard TT, Barr PB, Sanchez-Roige S, Madole JW, Driver MN, et al. Nature Neuroscience. 2021;24(10):1367-1376. doi:10.1038/s41593-021-00908-3
- Common liability to addiction and gateway hypothesis: theoretical, empirical and evolutionary perspective. Vanyukov MM, Tarter RE, Kirillova GP, Kirisci L, Reynolds MD, Kreek MJ, et al. Drug and Alcohol Dependence. 2012;123:S3-S17. PubMed
- Index of the transmissible common liability to addiction: heritability and prospective associations with substance abuse and related outcomes. Hicks BM, Iacono WG, McGue M. Drug and Alcohol Dependence. 2012;123:S18-S23. PubMed