
A 300-woman high-risk pregnancy study reported a striking before-after change after 4 weeks of daily Replika chatbot use: Pregnancy Anxiety and Stress Rating Scale scores fell from 54.05 to 10.15, p < 0.001.1 The result is a real signal for digital maternal support, but the no-control design makes it weak evidence that the chatbot itself caused the drop.
Research Highlights
- Anxiety scores fell sharply: mean PASRS total score dropped from 54.05 +/- 5.99 before chatbot use to 10.15 +/- 3.82 after 4 weeks, t = 98.507, p < 0.001.1
- The study tested high-risk pregnancies: 300 women in Egypt were enrolled, with 31.0% having hypertensive disorders, 27.0% gestational diabetes, and 24.0% placenta previa or abruption.1
- Usability was high: the BUS-11 chatbot usability score averaged 46.93 out of 55, and 97.0% agreed or strongly agreed that responses were quick.1
- Privacy was the weak spot: only 60.6% agreed or strongly agreed that their information was kept private and secure, the lowest user-experience domain.1
- Causal proof is missing: the 4-week study had no randomized control group, so training, weekly check-ins, expectancy, regression to the mean, or ordinary symptom fluctuation could explain part of the change.1
Pregnancy-related anxiety means anxiety tied directly to pregnancy, fetal health, childbirth, maternal role changes, and uncertainty about medical risk. High-risk pregnancy raises that baseline pressure because the pregnancy already involves complications such as hypertensive disorders, diabetes, placental problems, or risk of preterm labor.
AI emotional-support chatbots are conversational software systems that generate supportive text responses using natural-language processing. In maternal mental health, the practical promise is access: a tool can answer at 2 a.m., offer coping prompts, and create a low-friction place to name fear between prenatal visits.
The hard question is whether that access produces clinical benefit beyond attention, novelty, repeated self-reflection, and ordinary support from study staff.
PASRS Scores Fell From 54.05 to 10.15 After 4 Weeks
Elkashif et al. recruited 300 women with high-risk pregnancies at Al-Zahraa Hospital in New Damietta, Egypt. The study used a quasi-experimental pre-post design: participants completed baseline assessments, received training on the Replika chatbot, used it daily for 4 weeks, and then completed the same anxiety/stress measure again.1
The main outcome was the Pregnancy Anxiety and Stress Rating Scale (PASRS), a self-report scale scored from 0 to 60 in this study. Higher scores mean more pregnancy-related anxiety and stress.
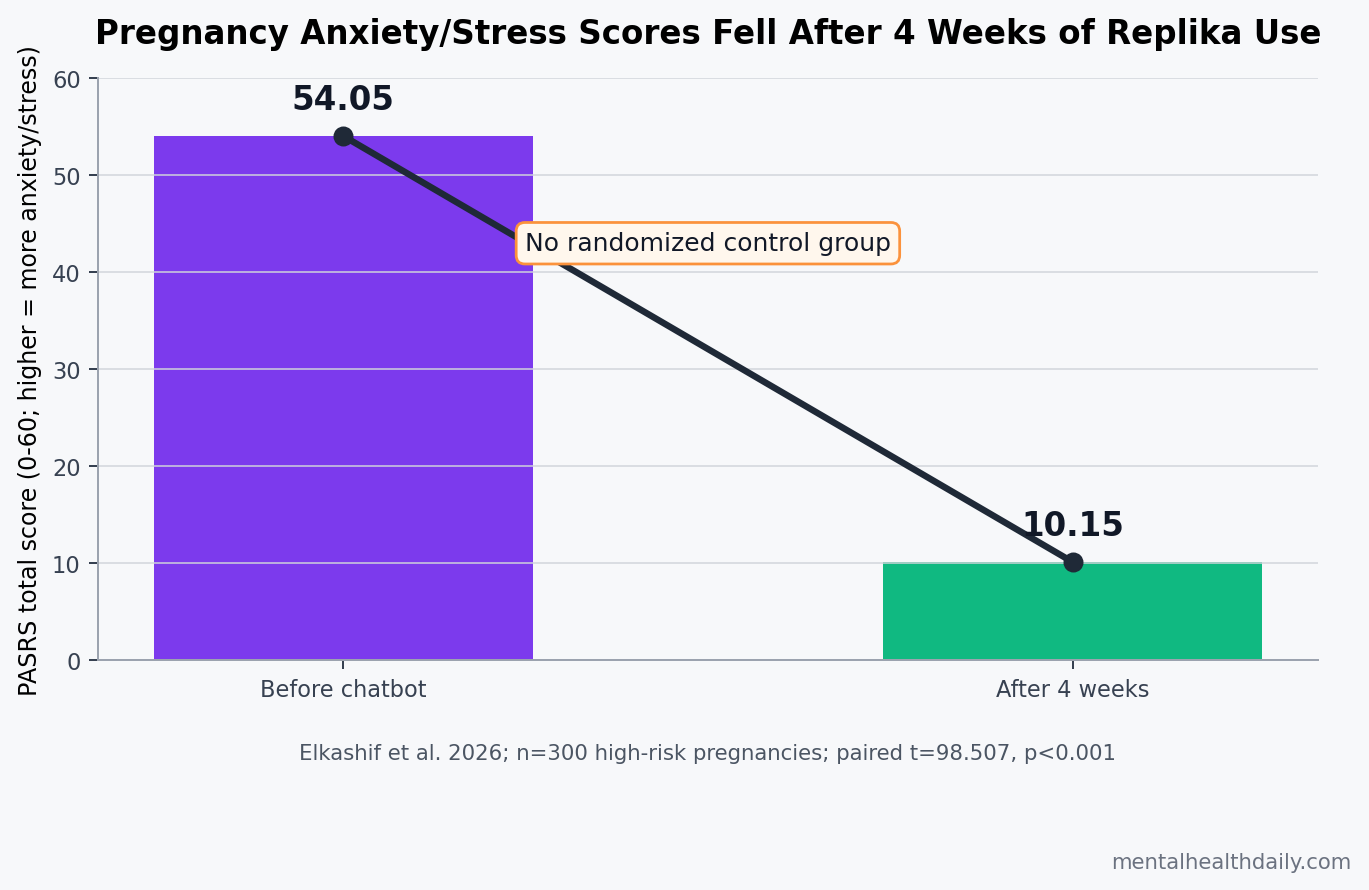
Main result: PASRS total score fell from 54.05 +/- 5.99 before the intervention to 10.15 +/- 3.82 afterward. The paired t-test was t = 98.507, p < 0.001.1
Item-level shift: worry about the child’s health moved from 96.7% often or always before the intervention to 0% often or always afterward. After 4 weeks, 88.3% reported that worry as “not at all” or “rarely.”1
Those numbers are large enough that they should not be hand-waved away. They also demand calibration. Without a control arm, the study cannot separate chatbot content from repeated measurement, study contact, training, technical support, reassurance from weekly calls, or natural symptom movement over a month.
The Cohort Had Real Pregnancy Risk, Not Mild Wellness Stress
The sample was clinically relevant. High-risk pregnancy conditions included hypertensive disorders in 93 women, gestational diabetes in 81, placenta previa or placental abruption in 72, preterm labor risk in 35, and hyperemesis gravidarum in 19.1
Most participants were in the second or third trimester: 40.7% at 14 to 27 weeks and 53.0% at 28 to less than 37 weeks. Rural and urban residence were almost evenly split, 50.7% vs. 49.3%. None had previously used an AI-based emotional-support tool.1
That last number is important for interpretation. A 0% prior-use rate means the intervention was novel for the entire cohort. Novelty can increase engagement, hope, and perceived support. It can also inflate short-term before-after improvements if the study does not include a comparison group with equal attention.
High Usability Does Not Solve the Privacy Problem
The chatbot was usable by standard user-experience measures. The overall BUS-11 score averaged 46.93 +/- 3.53 out of 55. Accessibility scored 8.56 out of 10, functionality 12.52 out of 15, conversation quality 17.57 out of 20, privacy 3.87 out of 5, and responsiveness 4.41 out of 5.1
Most item-level ratings were favorable:
- Access: 88.6% agreed or strongly agreed that they could easily access the chatbot when needed.
- Technical reliability: 85.0% agreed or strongly agreed that it was available without technical difficulties.
- Communication: 89.3% agreed or strongly agreed that it communicated clearly.
- Response speed: 97.0% agreed or strongly agreed that it responded quickly.
Privacy was weaker. Only 60.6% agreed or strongly agreed that their information was kept private and secure, while 35.0% were neutral.1 For a pregnancy mental-health tool, privacy is part of clinical safety. Users may disclose medical complications, fear about fetal health, relationship stress, trauma history, medication concerns, or suicidal thoughts.
Implementation implication: maternal-health chatbots need explicit data-handling explanations, emergency escalation rules, and limits on what the system stores or uses for model improvement. A chatbot that feels warm but has unclear privacy rules is not ready to be treated like ordinary prenatal infrastructure.
Perinatal Chatbot Evidence Is Still Mostly Feasibility Evidence
Adjacent studies point in the same cautious direction. McAlister et al. described the design and pilot testing of Moment for Parents, a chatbot built around pregnant and postpartum mental-health needs. That work supports feasibility and user-centered development more than definitive symptom efficacy.2
Chen et al. reviewed AI chatbots in women’s health and found a promising but heterogeneous evidence base. The problem is not that chatbots never help. The problem is that tools, populations, outcomes, and comparators differ so much that a positive pooled impression can hide fragile clinical assumptions.3
Pregnancy-anxiety measurement also complicates the field. Hadfield et al. found wide variation in tools used to measure pregnancy-related anxiety worldwide, which means a score change in one instrument does not automatically map onto diagnosis, impairment, fetal outcomes, or long-term maternal functioning.4
Non-AI interventions set a higher comparator standard. Feli et al. tested mindfulness-based counseling for anxiety and childbirth satisfaction in a randomized design.5 Chatbot studies that want clinical weight should be compared against credible low-intensity care, with each person’s baseline serving as a preliminary signal rather than the main comparator.
Why the No-Control Design Changes the Verdict
A pre-post design asks whether scores changed after the intervention. It does not prove why they changed. That distinction is especially important when the reported change is very large.
At least 5 non-chatbot explanations remain plausible:
- Study attention: participants received training and weekly check-in calls, which may have reassured them or increased perceived support.
- Expectation effects: users were told the tool was meant to provide emotional support, which can shape self-reported distress.
- Regression to the mean: people entering a study during high distress may improve on repeat measurement even without a specific treatment effect.
- Repeated self-monitoring: naming worries daily can itself reduce anxiety, even if the response comes from a simple script.
- Pregnancy-course effects: symptoms can change over 4 weeks as medical information, fetal monitoring, family support, or obstetric plans become clearer.
None of those explanations refutes the chatbot signal. They define what the study can and cannot support. The safest verdict is that Replika use was associated with a dramatic short-term anxiety/stress reduction in a high-risk pregnancy cohort, while controlled trials are needed before calling it an effective treatment.
What a Stronger AI Pregnancy-Anxiety Trial Would Need
A stronger study would randomize participants to chatbot support, an active digital control, and usual care. The active control matters because attention, reminders, psychoeducation, and weekly check-ins can all lower anxiety without requiring generative AI.
Essential outcomes: pregnancy-specific anxiety, general anxiety, depressive symptoms, sleep, functioning, care adherence, emergency contacts, user trust, adverse chatbot responses, privacy comprehension, and sustained effects after the chatbot period ends.
Essential safety gates: crisis escalation, hallucinated medical advice, privacy disclosures, clinician review pathways, data retention limits, and behavior when a user asks pregnancy-specific medical questions outside the chatbot’s competence.
Commercial chatbots add another layer. Replika is not a prenatal mental-health device designed only for pregnant users. A study of one commercial app should not be generalized to every AI support tool, and a positive usability score should not be confused with regulatory, clinical, or data-security clearance.
Questions About AI Chatbots for Pregnancy Anxiety
Did the Replika study prove that AI chatbots treat pregnancy anxiety?
No. The study showed a large before-after PASRS score drop after 4 weeks of daily use, but it did not include a control group. It supports feasibility and a strong symptom signal, not causal proof.
Was the score change clinically impressive?
Yes, as a raw within-person change. A mean drop from 54.05 to 10.15 on a 0 to 60 scale is large. The uncertainty is attribution: the design cannot show how much came from the chatbot vs. study attention, expectation, repeated self-monitoring, or other changes.
Should high-risk pregnant women use chatbots instead of prenatal mental-health care?
No. Chatbots may be useful as between-visit support, mood tracking, or coping prompts. They should not replace obstetric care, mental-health evaluation, medication decisions, crisis support, or human follow-up when distress is severe.
What was the clearest implementation warning?
Privacy. Usability was high, but only 60.6% agreed or strongly agreed that their information was private and secure. Pregnancy mental-health chatbots need transparent data rules before routine use.
References
- Elkashif MML, Rahmath M, Mohamed SA, Hamed SGA, Sheashaa DM, Abdellatif MS. The impact of artificial intelligence-based emotional support tools on anxiety and stress levels in high-risk pregnant women. Scientific Reports. 2026. doi:10.1038/s41598-026-49427-w
- McAlister K, Baez L, Huberty J, Kerppola M. Chatbot to support the mental health needs of pregnant and postpartum women (Moment for Parents): design and pilot study. JMIR Formative Research. 2025;9:e72469. doi:10.2196/72469
- Chen X, Li Y, Zhang Z, Xu W. The effects of artificial intelligence chatbots on women’s health: a systematic review and meta-analysis. Healthcare. 2023;12(5):534. doi:10.3390/healthcare12050534
- Hadfield K, Akyirem S, Sartori L, Abdul-Latif AM, Akaateba D, Bayrampour H, et al. Measurement of pregnancy-related anxiety worldwide: a systematic review. BMC Pregnancy and Childbirth. 2022;22:331. doi:10.1186/s12884-022-04661-8
- Feli R, Heydarpour S, Yazdanbakhsh K, Heydarpour F. The effect of mindfulness-based counselling on the anxiety levels and childbirth satisfaction among primiparous pregnant women: a randomized controlled trial. BMC Psychiatry. 2024;24:964. doi:10.1186/s12888-024-06442-3
- Park G, Chung J, Lee S. Effect of AI chatbot emotional disclosure on user satisfaction and reuse intention for mental health counseling: a serial mediation model. Current Psychology. 2023;42:28663-28673. doi:10.1007/s12144-022-03932-z