
A 2026 ABCD Study preprint involving 11,868 youth found stable time-ordered predictors of teen substance-use initiation, but the adjusted effects were small: most estimates ranged from −0.01 to 0.02 initiation-probability points per 1-SD predictor increase.
Research Highlights
- Large ABCD panel: Wei et al. analyzed 11,868 youth with repeated observations and interval-level initiation outcomes for alcohol, nicotine, cannabis, and any substance.1
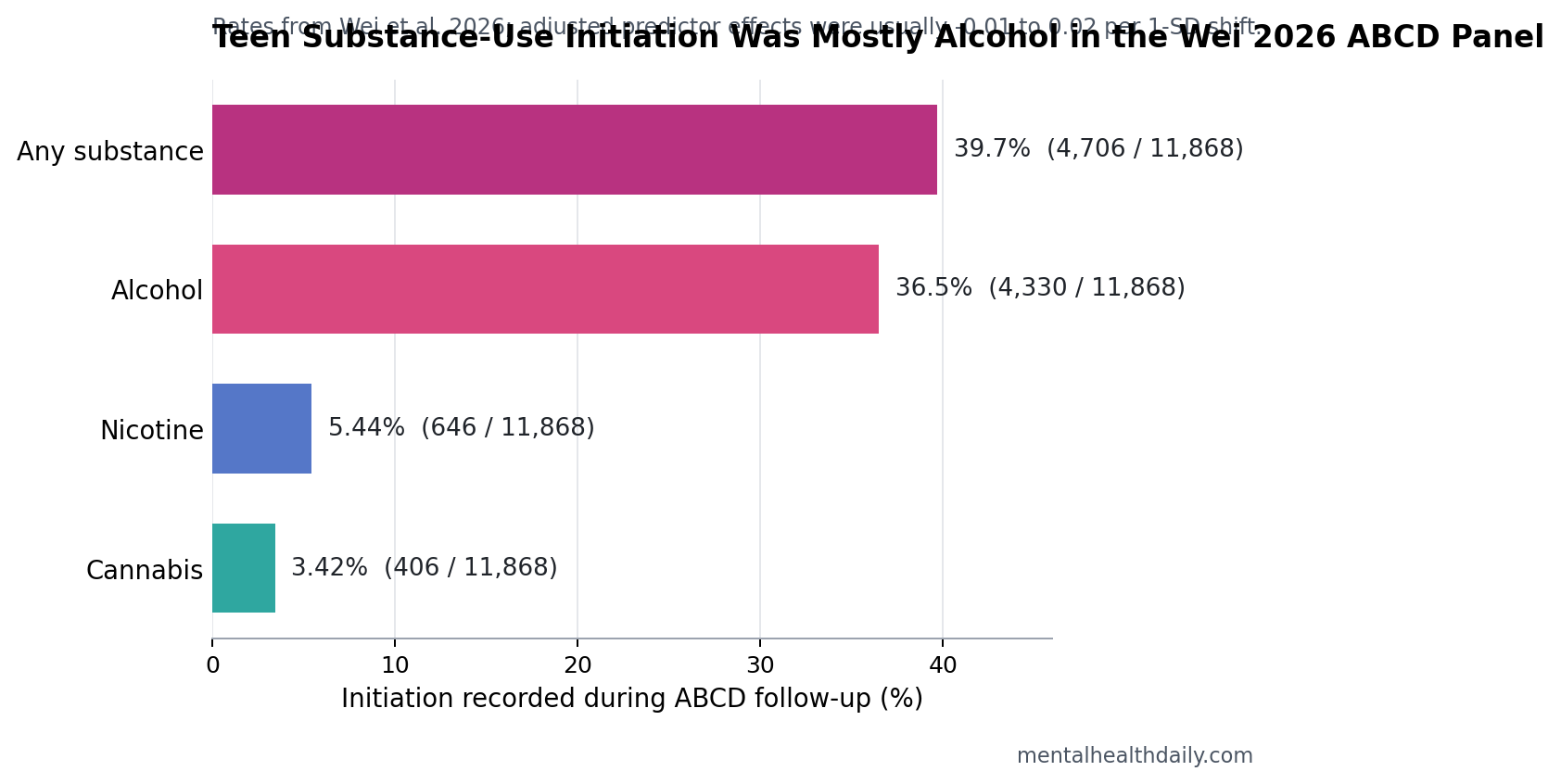
- Alcohol drove most initiation: alcohol initiation was recorded in 4,330 of 11,868 youth (36.5%), compared with nicotine in 646 (5.44%) and cannabis in 406 (3.42%).1
- Predictors were stable, not large: many lagged predictors reached high bootstrap stability, but adjusted effects were usually between −0.01 and 0.02 per 1-SD predictor increase.1
- Ordinary context beat magic biomarkers: sleep, parental monitoring, family environment, peer behavior, screen time, behavioral risk, and genetic liability repeatedly appeared in the risk map, consistent with earlier ABCD prediction work.2
- Causal language needs restraint: double machine learning can adjust high-dimensional observational data, but it cannot make unmeasured family, school, neighborhood, and peer confounding disappear in a preprint cohort analysis.1
ABCD means the Adolescent Brain Cognitive Development Study, a large U.S. cohort that follows children from late childhood into adolescence with repeated measures of behavior, health, family context, environment, genetics, and brain development. This paper is not a clinical risk calculator for a specific teenager; it is a high-dimensional map of which earlier variables tended to precede later first use.
Calibrated interpretation: the model found no giant lever for preventing substance use. It found a broad, familiar pattern: risk is distributed across sleep, family structure, peer context, behavioral regulation, and genetic liability, and the strongest prevention clues may be ordinary developmental variables measured repeatedly rather than expensive one-time biomarkers.
11,868 Youth Were Followed for First Alcohol, Nicotine, and Cannabis Use
Wei et al. used ABCD release 5.1 and built a longitudinal panel from 11,868 children. Each child could contribute multiple time intervals, and each interval was coded for whether initiation occurred during that interval. Once a child had already initiated a substance, later rows were no longer treated as at-risk rows for that specific outcome.
Initiation was uneven across substances:
- Alcohol: 4,330 of 11,868 youth, or 36.5%.
- Nicotine: 646 of 11,868 youth, or 5.44%.
- Cannabis: 406 of 11,868 youth, or 3.42%.
- Any substance: 4,706 of 11,868 youth, or 39.7%.
That distribution matters for interpretation. A model for “any substance” in this age window is heavily shaped by alcohol initiation, because alcohol events were far more common than nicotine or cannabis events. Cannabis and nicotine estimates are still useful, but they come from smaller event counts and therefore carry more uncertainty.
Among youth who initiated, the estimated mean time from baseline year age was 20.83 months for alcohol, 22.65 months for nicotine, 23.30 months for cannabis, and 20.93 months for any substance. The paper also reported demographic differences: alcohol and any-substance initiation rates were higher in males than females, and alcohol initiation varied across race and ethnicity groups.
Lagged Prediction Protected Timing Better Than Baseline-Only Screening
Lagged predictors are variables measured before the outcome interval being predicted. In this paper, earlier sleep, family, peer, behavioral, and genetic variables were used to predict later initiation rather than same-time initiation. That design reduces one common error in observational substance-use research: treating a variable measured after or during first use as if it came before first use.
The first modeling stage used a Granger-inspired approach. Granger-style prediction is weaker than true biological causation: past values of one variable improve prediction of a later outcome after time ordering is respected. The researchers used elastic-net logistic regression, a method that can handle many correlated predictors by shrinking weak coefficients while retaining stronger signals.
They then used bootstrap stability selection, which repeatedly refits a model on resampled participants and tracks how often a predictor survives. A predictor selected in 80% or more of resamples is more robust than a variable that appears once because of noise in a single split.
The second stage estimated adjusted effects for stable predictors with double machine learning, a causal-inference framework that uses flexible prediction models to adjust for many covariates before estimating the relationship between one predictor and one outcome. The paper used random forests for nuisance models, group-based cross-fitting so the same person did not leak across training folds, and cluster-robust standard errors for repeated observations.
Sleep, Family, Peer, and Behavioral Variables Repeated Across Outcomes
Across graph discovery and effect estimation, the same broad domains kept appearing: sleep and circadian rhythm, parental and family environment, peer relationships, pubertal development, prior substance-related exposure, behavioral traits, and genetic risk.
Alcohol and any substance: top predictors spanned polygenic risk scores, parental substance use, family environment, early-life factors, behavioral measures, and health-related measures. Because alcohol initiation was common, these estimates carry much of the weight in the overall “any substance” pattern.
Cannabis: predictors were more concentrated in behavioral traits, family and parenting factors, and sleep/circadian measures. The paper singled out parental monitoring as the strongest protective association for cannabis initiation.
Nicotine: increased risk was linked to genetic liability, sleep and circadian measures, screen time, behavioral factors, and peer-related behavior. Nicotine had fewer initiation events than alcohol, so the direction of the pattern is more important than treating each predictor as a stand-alone prevention target.
The strongest editorial correction is that “stable” is not the same as “large.” A variable can be selected repeatedly across bootstrap samples and still have a small adjusted effect. Wei et al. reported most adjusted estimates between about −0.01 and 0.02 on the probability scale per 1-SD increase in a predictor, with some confidence intervals including zero.
Earlier ABCD Work Points to the Same Practical Layer
Green et al. studied predictors of substance-use initiation by early adolescence in ABCD and found that 982 of 6,829 substance-naive youth, or 14.4%, initiated by the 3-year follow-up.2 Their final model retained variables from demographic, self and peer substance-use, parenting, mental-health, physical-health, and culture/environment domains. Resource-intensive neuroimaging blocks did not outperform ordinary self-, peer-, and family-related data for that early prediction question.
Ivanov et al. reached a similar prevention frame in a large drug-naive adolescent cohort: first use, especially alcohol, was not randomly scattered across development.3 Adolescent substance initiation could be studied prospectively before substance-use disorder existed, and early behavioral, social, and developmental features carried signal.
A later JAMA Network Open analysis tested neuroanatomical variability against substance-use initiation in late childhood and early adolescence.4 Brain measures can be scientifically interesting, but the practical prevention problem still comes back to the same question: which measurable childhood context variables add actionable signal beyond the obvious burden of cost, scale, and noise?
Wei et al. extended that line of work by turning the predictor field into a time-varying panel. Instead of asking only which baseline variables predicted later use, the model asked whether earlier changes in the environment, sleep, behavior, peer context, family context, and genetic liability preceded initiation in later intervals.
Double Machine Learning Does Not Remove Observational Limits
The paper’s title uses “causal interface,” and the methods are stronger than ordinary correlation screening. Still, the underlying data are observational. Unmeasured confounding means an unrecorded factor could influence both the predictor and the outcome, making a predictor look more causal than it is.
Several limits keep the result in the hypothesis-generating lane:
- Preprint status: the manuscript had not yet been peer reviewed, and the PDF itself carried the standard medRxiv warning that it should not guide clinical practice.
- Measurement error: first use, sleep, family variables, peer exposure, and behavior are partly self- or parent-reported, which can blur timing and effect estimates.
- Small effect sizes: a 0.02 probability-scale estimate per 1-SD predictor increase is not a stand-alone screening rule.
- Unequal event counts: alcohol initiation was common, while nicotine and cannabis initiation were much rarer in the analyzed intervals.
- Model dependence: stability selection and double machine learning depend on the measured covariate set, lag choices, nuisance models, and how missing values were handled.
The right prevention conclusion is not “sleep disturbance causes teen substance use” or “parental monitoring prevents cannabis initiation” in a one-variable way. The better-supported conclusion is that teen substance-use risk appears distributed across repeated, measurable developmental conditions, and those conditions may be better early-warning surfaces than one-off biological screens.
Prevention Should Treat Risk as a Pattern, Not a Single Trigger
For schools, families, clinicians, and public-health programs, the most useful signal is the multi-domain pattern. Sleep disturbance, weak structure, peer exposure, behavioral risk, screen time, and genetic liability may each move risk only modestly, but their repeated co-occurrence can help identify youth who need earlier support.
Practical interpretation: repeated low-burden measures may beat expensive one-time tests. Asking about sleep regularity, supervision, peer exposure, family stress, and early experimentation is not technologically flashy, but those variables are scalable and closer to the modifiable layer of prevention than many biomarker panels.
Clinical caution: a model like this should not be used to label a child as destined for addiction. It is better suited for population-level prevention design, research prioritization, and deciding which domains deserve repeated measurement in future trials or school-health systems.
Questions About Teen Substance-Use Prediction
Did the Wei analysis prove that changing sleep or parenting prevents substance use?
No. The analysis used lagged timing and double machine learning to reduce some bias, but it remained observational. It can identify candidate prevention targets and time-ordered associations, not prove that changing one predictor would prevent initiation.
Why are the alcohol numbers so much higher than nicotine or cannabis?
Alcohol use tends to start earlier and is more common in this age range than nicotine or cannabis. In Wei et al., 36.5% of youth initiated alcohol compared with 5.44% for nicotine and 3.42% for cannabis.
Are small effects still useful?
Yes, if they are interpreted as part of a risk pattern. A single 0.01 or 0.02 probability-scale effect is too small for deterministic screening, but many small, repeated, modifiable signals can still guide prevention design.
What should future studies test next?
The strongest next step would be testing whether repeated measurement of sleep, family structure, peer exposure, and behavioral risk improves prevention targeting beyond ordinary questionnaires, and whether interventions on those domains actually reduce initiation.
References
- Wei M, Yadlapati L, Peng Q. A Machine Learning Based Causal Interface for Time Varying Environmental Predictors of Substance Use Initiation in the ABCD Study. medRxiv. 2026. doi:10.64898/2026.04.15.26350988
- Green RJ, Wolf BJ, Chen A, et al. Predictors of Substance Use Initiation by Early Adolescence. American Journal of Psychiatry. 2024;181(5):423-433. doi:10.1176/appi.ajp.20230882
- Ivanov I, Parvaz MA, Velthorst E, et al. Substance Use Initiation, Particularly Alcohol, in Drug-Naive Adolescents: Possible Predictors and Consequences From a Large Cohort Naturalistic Study. Journal of the American Academy of Child & Adolescent Psychiatry. 2021;60(5):623-636. doi:10.1016/j.jaac.2020.08.443
- Miller AP, Baranger DAA, Paul SE, et al. Neuroanatomical Variability and Substance Use Initiation in Late Childhood and Early Adolescence. JAMA Network Open. 2024;7(12):e2452027. doi:10.1001/jamanetworkopen.2024.52027
- Lisdahl KM, Tapert SF, Sullivan EV, et al. Adolescent substance use initiation and long-term neurobiological outcomes: insights, challenges and opportunities. Molecular Psychiatry. 2024;29:2211-2222. doi:10.1038/s41380-024-02471-2