
A 2026 preprint found that an independent supervisory safety agent detected suicide-risk signals in 205 of 224 synthetic evaluations, compared with 41 of 224 for native ChatGPT Health crisis safeguards.1 The result is a strong benchmark signal for external monitoring, not proof that AI systems can safely manage suicidal patients without human oversight.
Research Highlights
- Supervisory monitoring detected more crisis cases: the independent safety agent flagged 205 of 224 evaluations (91.5%) vs. 41 of 224 (18.3%) for native ChatGPT Health safeguards.1
- Most discordance favored the external layer: 166 paired evaluations were detected only by the supervisory system, while 2 were detected only by ChatGPT Health.1
- Native safeguards still caught some cases: 39 evaluations were detected by both systems, so the finding is not that built-in crisis behavior was absent.1
- Some synthetic crises still slipped through: 17 evaluations were detected by neither system, which is the clinically uncomfortable part of the benchmark.1
- Evidence strength is limited: the study used 224 synthetic evaluations, not real patients, multi-turn crisis care, or post-discharge outcomes.1
Suicide-risk triage means identifying signs that a person may harm themselves and escalating to an appropriate crisis response. In human care, that requires context, intent, plan, means, protective factors, and follow-up. In AI systems, the first hard problem is more basic: whether the system even notices a crisis signal before producing ordinary advice.
Supervisory safety architecture means a separate monitoring layer that watches model interactions and can trigger safety behavior outside the base model’s normal response path. The Trivedi et al. study tested that external-monitoring idea against native ChatGPT Health safeguards in synthetic suicide-related vignettes.1
205 of 224 Suicide-Risk Evaluations Triggered the Supervisory Agent
Trivedi et al. built 224 paired evaluations from 7 suicide-risk scenarios, with 16 vignette variants per scenario-condition pairing. The study compared how often an independent supervisory system detected suicide risk vs. how often native ChatGPT Health safeguards reacted to the same synthetic cases.1
Detection gap: the supervisory system detected 205 of 224 evaluations, or 91.5%. Native ChatGPT Health safeguards detected 41 of 224, or 18.3%. In the discordance breakdown, 166 evaluations were supervisory-only detections, 2 were native-only detections, 39 were caught by both, and 17 were missed by both.
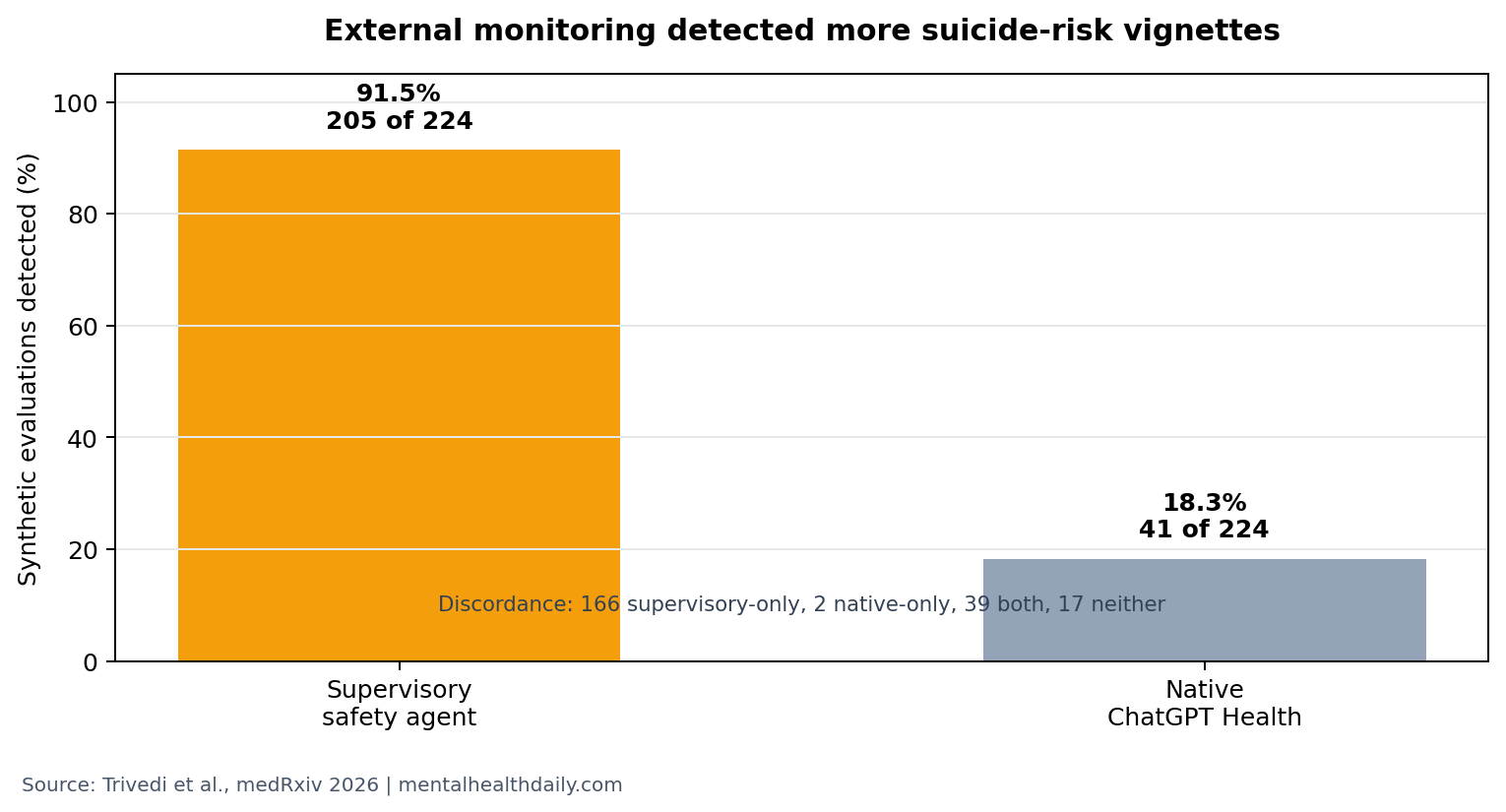
The headline number is not subtle. If a synthetic crisis benchmark is a first-pass stress test, the external layer outperformed native safeguards by a wide margin. That does not make the external layer clinically sufficient; it shows that relying only on the base model’s built-in crisis behavior can leave a large detection gap.
Asynchronous Monitoring Is a Different Safety Tool Than a Prompt Warning
The strongest implementation detail is that guardrail activations came from asynchronous monitoring. Asynchronous monitoring means a separate process can inspect the interaction in parallel, instead of waiting for the base model to self-diagnose risk inside the same response. That design matters because a model can sound empathic and still fail to escalate.
In clinical AI governance, external oversight has been proposed because average response quality is a poor safety measure. A chatbot that handles 95 ordinary mood-support prompts fluently can still be unacceptable if it mishandles 1 high-risk suicidal prompt. Prior digital-health discussions have therefore emphasized crisis-specific failure analysis, escalation rules, and auditable safeguards rather than general fluency scores.2
Sarkar et al. made the same problem visible from the explainability side: mental-health conversational agents cannot be evaluated only by whether their answers sound supportive, because users and reviewers also need to know why a safety decision was triggered, what uncertainty remained, and when human review entered the loop.2 That is a different standard than ordinary chatbot helpfulness.
For suicide-risk monitoring, the useful question is operational:
- Can the system detect risk early?
- Can it preserve enough context for review?
- Can it avoid silently downgrading high-risk prompts?
- Can it route the interaction to a human or emergency pathway before the conversation drifts back into generic coaching?
Practical implication: a suicide-risk safety layer should be evaluated as its own system. It needs sensitivity, false-positive review, timing, escalation behavior, logging, and human handoff rules. A warning phrase inside a model prompt is not the same thing as a separately tested supervisory architecture.
17 Missed Evaluations Keep Human Oversight in the Frame
The 17 evaluations missed by both systems are not a rounding error in a suicide-risk setting. A benchmark miss does not equal a patient death, but it points to the failure class that matters most: high-stakes prompts that receive no crisis escalation from either the model or the monitor.
That is why the result should not be translated into “AI can manage suicide risk.” It supports a narrower claim: independent safety monitoring may detect many crisis signals that native safeguards miss. In real deployment, suicide-risk AI systems would still need constrained use cases, human escalation, emergency-resource routing, audit trails, and clear liability boundaries.
Clinical chatbot safety research has repeatedly run into the same distinction. Fluent language can hide weak triage. Empathic tone can coexist with poor risk stratification. A response can sound caring while failing to ask about plan, access to means, immediacy, or protective supervision.
Heston’s health-safety prompt work fits that pattern because it treated generative AI answers as safety objects with triage consequences.3 A model can mention crisis resources and still fail the harder task if the response buries urgency, offers reassurance before assessment, or gives the user an easy path to disengage from human help.
Missed cases are not the only risk: false positives also matter. A monitor that escalates every ambiguous sadness prompt would create alarm fatigue, unnecessary intrusion, and workflow overload. The Trivedi et al. benchmark mainly establishes the sensitivity problem: native safeguards missed too much. It does not settle the specificity problem: how often an external monitor would over-escalate lower-risk conversations in a real service.
Specificity also changes the ethics of deployment. A high-sensitivity monitor may be appropriate inside a staffed crisis workflow, where extra alerts can be reviewed quickly. The same threshold may be reckless inside a lightly supervised wellness app, where alerts create promises the service cannot fulfill. The benchmark result therefore points toward setting-specific validation, not a single universal cutoff.
Benchmark Evidence Is Not Patient-Outcome Evidence
This was a preprint benchmark using synthetic vignettes. That design is useful because it can stress-test a system against standardized crisis scenarios, but it cannot prove that patients are safer. It also cannot test whether users would disclose the same details in real conversations, whether multi-turn exchanges would change detection, or whether false positives would overwhelm human reviewers.
What the design can support:
- External monitoring detected more synthetic suicide-risk signals than native safeguards in this benchmark.
- Native safeguards missed many cases that the supervisory layer flagged.
- Some crisis-like prompts remained undetected even with the supervisory system present.
What the design cannot support:
- It cannot show reduced suicide attempts, emergency visits, hospitalizations, or deaths.
- It cannot prove safety in messy multi-turn conversations with real distressed users.
- It cannot define the correct threshold for escalation without false-positive and workflow data.
The next validation layer would need to look more like a clinical safety study than a prompt leaderboard. Useful endpoints would include time to escalation, reviewer agreement, false-positive burden, user disclosure after escalation, and whether the system preserves context for crisis workers. Those endpoints are less flashy than a 91.5% detection rate, but they are closer to the operational question a mental-health service has to answer.
Blease et al. argued for governance around clinical large language models because liability, transparency, and human oversight cannot be retrofitted after deployment.4 Suicide-risk detection is the sharp version of that problem. A safety layer needs a written escalation policy tied to its benchmark score.
That policy has to specify at least 4 things:
- Trigger threshold: what level of ideation, intent, plan, means, or behavior activates the supervisory layer.
- Human handoff: who receives the alert, how quickly they review it, and what happens when no reviewer is available.
- User-facing response: whether the system asks follow-up risk questions, gives crisis resources, stops ordinary coaching, or routes to emergency support.
- Audit trail: what prompt context, model output, monitor decision, and reviewer action are logged for later safety review.
Without those implementation details, “supervisory safety agent” can become another broad label. With them, it becomes a testable safety system: imperfect, but easier to audit than a base model asked to police its own high-stakes failures.
Questions About AI Suicide-Risk Safety Agents
Does this mean ChatGPT Health is unsafe?
The study shows that native safeguards detected far fewer synthetic suicide-risk evaluations than the external supervisory system. It does not fully evaluate every possible ChatGPT Health setting, prompt, user behavior, or clinical deployment.
Should mental-health apps use independent monitoring layers?
For any AI system that may encounter suicidal ideation, the benchmark supports testing independent monitoring rather than assuming the base model’s crisis behavior is enough. The monitoring layer still needs real-world validation and human escalation.
Which claim is safest from this benchmark?
Independent supervisory monitoring improved synthetic suicide-risk detection in this 224-evaluation benchmark. It is not evidence that AI can independently triage or treat suicidal people.
References
- Trivedi K, et al. An independent supervisory safety agent improves reaction of large language models to suicidal ideation. medRxiv. 2026. doi:10.64898/2026.04.13.26350757
- Sarkar S, et al. A review of the explainability and safety of conversational agents for mental health to identify avenues for improvement. Frontiers in Artificial Intelligence. 2023. doi:10.3389/frai.2023.1229805
- Heston TF. Evaluating generative AI responses to health safety prompts. JMIR Mental Health. 2023. doi:10.2196/51204
- Blease C, et al. Generative AI and governance in clinical communication. Lancet Digital Health. 2024. doi:10.1016/s2589-7500(23)00206-6