
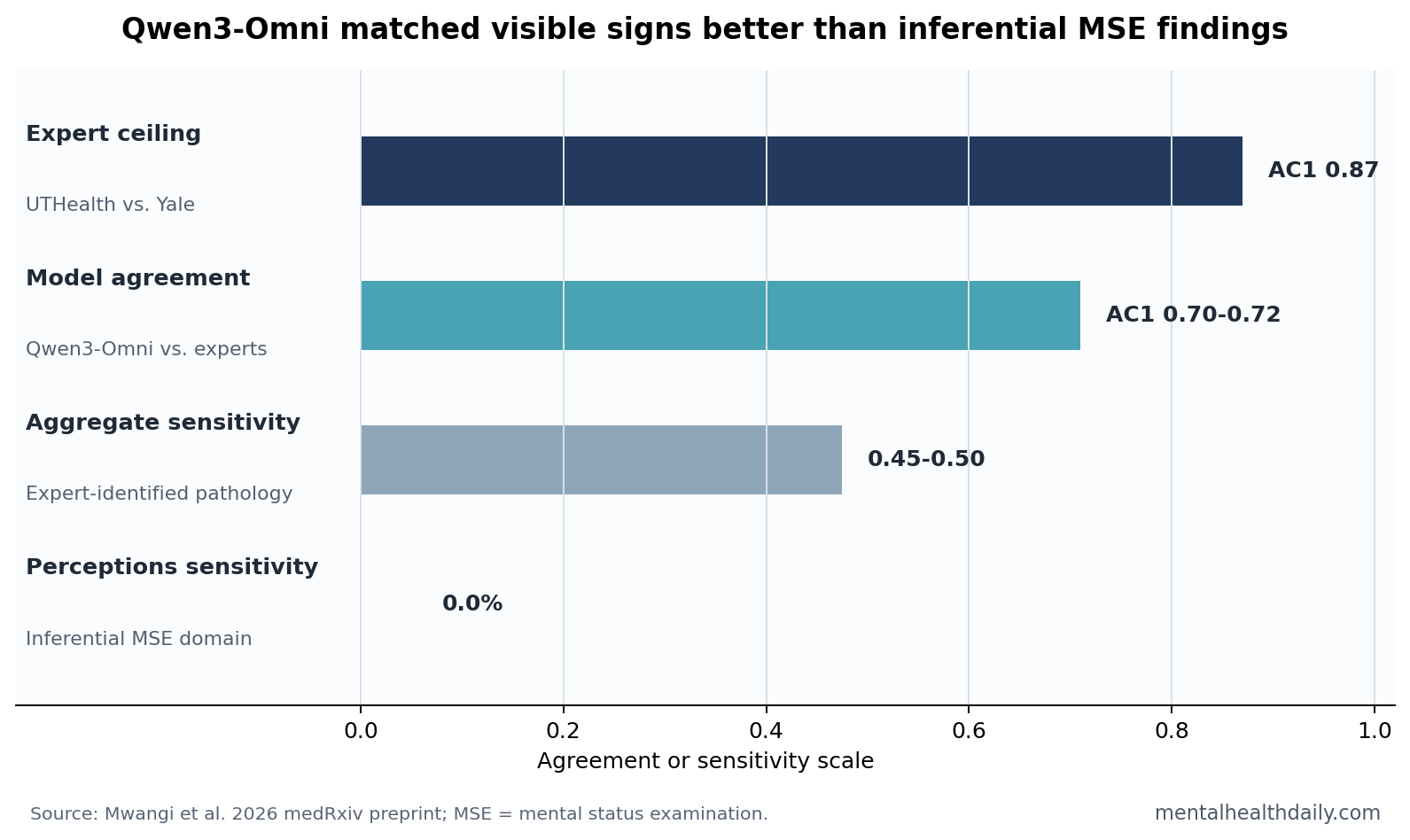
A 2026 medRxiv benchmark found Qwen3-Omni reached only moderate agreement with expert mental status examination panels: AC1 = 0.70 vs. UTHealth and 0.72 vs. Yale, below expert agreement of 0.87; its aggregate performance masked a clinical reasoning gap, overcalling visible signs such as speech and affect while missing delusions and perceptual abnormalities.1
Research Highlights
- Expert agreement set a high ceiling: UTHealth and Yale panels agreed across 396 item-level classifications with AC1 = 0.87 and 90.7% accuracy.1
- Qwen3-Omni stayed below that ceiling: model-to-expert AC1 was 0.70 vs. UTHealth and 0.72 vs. Yale, with aggregate sensitivity only 0.45-0.50.1
- Inferential symptoms were the weak point: perceptions had 0.0% model sensitivity despite expert pathology prevalence of 8.3% at UTHealth and 5.6% at Yale.1
- Clinical ambiguity amplified errors: when experts agreed, the model erred on 17% of items; when experts disagreed, its error rate rose to 41%-59%.1
- Compression worsened reasoning: a 4-bit quantized model dropped from 80.6% to 66.8% accuracy vs. Yale, with inferential domains declining more than observable domains.1
Mental status examination (MSE) means the structured psychiatric description of appearance, behavior, speech, mood, affect, thought process, thought content, perception, cognition, insight, and risk. It is not a blood test. Clinicians infer some findings from directly visible behavior, but other findings require mapping what a patient says into a psychiatric category.
Multimodal foundation models are AI systems that process more than text, such as video, audio, images, and language in the same model. That makes them plausible tools for MSE-style tasks because real psychiatric assessment depends on face, voice, movement, speech content, and time-course information at once.
Expert Panels Agreed More Strongly Than the AI Model
Mwangi et al. used 9 standardized-patient videos from an existing MSE teaching resource. The videos represented 3 simulated adult patients portraying schizophrenia, obsessive-compulsive disorder, and bipolar disorder across 3 timepoints of rising symptom severity.1 Each video was scored across 10 MSE domains and 44 binary items, creating 396 item-level classifications.
Two independent expert panels, one at UTHealth and one at Yale, served as the human benchmark. Their agreement was strong: AC1 = 0.87, 95% CI 0.79-0.94, with 90.7% accuracy. Discordant counts were almost symmetric, 18 vs. 19, and McNemar’s test was nonsignificant, p = 0.82, which argues against one site using a systematically lower or higher threshold.
Gwet’s AC1 is an inter-rater agreement statistic designed to behave better than Cohen’s kappa when positive findings are uncommon. That point is load-bearing here because expert-annotated pathology prevalence was only 16.9%-17.2%. In a low-prevalence MSE dataset, a model can look deceptively accurate by saying “absent” most of the time.
Qwen3-Omni did not collapse. It reached AC1 = 0.70 vs. UTHealth and AC1 = 0.72 vs. Yale. Those are moderate-to-substantial agreement numbers, not random guessing. The calibration problem is that the model stayed below the human-human ceiling, and its sensitivity to expert-identified pathology was only 0.45 vs. UTHealth and 0.50 vs. Yale.
Visible Signs Were Overcalled While Delusions and Perceptions Were Missed
Lower total agreement was only the surface signal. The model’s errors had a psychiatric shape. Observable domains, such as affect, mood, and speech, showed high sensitivity but weak specificity. In affect and mood, sensitivity reached 0.91 vs. UTHealth and 1.00 vs. Yale, but specificity fell to 0.68 and 0.67. In speech, sensitivity was 0.78-0.88 while specificity was only 0.52-0.54.1
Plainly: Qwen3-Omni noticed visible or audible abnormalities, but it used a liberal threshold and over-predicted pathology in those domains.
Inferential domains showed the opposite failure mode. Inferential symptoms are findings that depend on interpreting subjective mental content beyond visible behavior. Hallucinations, delusions, obsessions, and some thought-process abnormalities require the model to understand what the patient’s words mean clinically.
Perceptions were the sharpest failure case. The model predicted 0.0% positive despite expert pathology prevalence of 8.3% at UTHealth and 5.6% at Yale. Delusion sensitivity was also low, 0.12 vs. UTHealth and 0.17 vs. Yale. The study team reported that the model could transcribe verbal descriptions of hallucinatory experiences but failed to classify that speech as a perceptual abnormality.1
Clinical interpretation: the model often captured raw video and audio signals, then failed at the psychiatric mapping step. That is a different problem from camera quality, speech recognition, or missing data. It is the difference between hearing a statement and knowing what mental-status category the statement supports.
Clinical Complexity Reduced Model Accuracy by 13-14 Points
Model performance also worsened as the simulated presentations became more severe. Against UTHealth, accuracy declined from 84.8% at T0 to 80.3% at T1 and 71.2% at T2. Against Yale, accuracy declined from 87.1% to 81.8% and 72.7%. That is a 13-14 percentage-point drop from the mildest to the most severe timepoint.1
Higher symptom prevalence creates more chances to disagree, but the model’s sensitivity did not improve as pathology became more obvious. Against UTHealth, sensitivity stayed around 0.41-0.46 across timepoints. Against Yale, it was 0.63 at T0, 0.47 at T1, and 0.49 at T2.
Human agreement was more resilient. Inter-expert accuracy was 96.2% at T0 and 87.9% at both T1 and T2. More severe presentations made the task harder for humans too, but the model lost more ground in the exact setting where psychiatric decision support would need to become safer, not looser.
Expert Disagreement Was a Real Difficulty Signal, Not Noise
The most useful design feature is the 2-panel benchmark. Many clinical AI papers compare a model with a single reference panel and quietly treat that panel as ground truth. Psychiatry makes that fragile because subjective symptoms, threshold judgments, and domain wording vary across clinicians.
Blaabjerg et al. had already shown variability between psychiatrists across MSE domains.3 The new benchmark converted that idea into a model-calibration test. Experts agreed on 359 of 396 classifications and disagreed on 37. When the experts agreed, Qwen3-Omni’s baseline error rate was 17%. When experts disagreed, the model’s error rate rose to 41% vs. Yale and 59% vs. UTHealth.
Those are 2.3-fold and 3.4-fold increases. The model was not failing uniformly. It failed hardest where human clinical interpretation was already less settled.
Benchmark implication: psychiatric AI should not be evaluated only against a single binary answer key. A better standard measures the model against the distribution of expert agreement, then asks whether model errors cluster in clinically ambiguous domains or in domains where experts already agree.
Prior MSE Automation Was Narrower Than Full Clinical Reasoning
Automated MSE work did not begin with this preprint. Liu et al. described aiMSE, an online system that used camera, microphone, speech, and language signals to detect MSE abnormalities and recommend further evaluation. Its 14-person feasibility study supported the idea that multimodal signals can capture some mental-status information remotely.4
The Qwen3-Omni benchmark asks a harder question. Instead of showing whether a system can detect selected abnormalities, it asks whether a general multimodal model can classify 10 MSE domains across diagnoses and timepoints while staying calibrated against independent expert panels.
General medical AI gives the same warning from another direction. In a randomized clinical trial, Goh et al. found that access to a large language model chatbot did not improve physicians’ diagnostic reasoning on challenging cases, even though the model alone performed well.6
Aykut et al. likewise benchmarked a multimodal model against emergency physicians for burn assessment, a reminder that visual medical AI performance depends heavily on the exact task and reference standard.5
Psychiatric MSE adds a special burden: visible behavior, spoken language, timing, and subjective report all need to be mapped into a clinical taxonomy.
Preprint and Simulated-Video Limits Keep the Result Narrow
Evidence-strength note: this is a preprint, not a peer-reviewed clinical deployment study. The benchmark used 9 simulated-patient videos, 3 diagnoses, and 396 binary classifications. The videos came from professional actors portraying scripted psychiatric presentations, not real-world patients with messy lighting, inconsistent audio, guarded disclosure, intoxication, medication effects, cultural variation, or comorbid illness.
The controlled setup is a strength for error isolation. It lets researchers know which symptoms were intended and compare domains under stable conditions. It is also a limit. Simulated presentations may be clearer than real encounters, and each diagnosis was represented by 1 simulated patient. Diagnosis-level findings can therefore be partly person-level findings.
Consensus ratings are another limit. Expert panels resolved disagreements before final scoring, which may create cleaner agreement than fully independent raters would show. The model was also tested in a single inference pass per item, with no test-retest reliability estimate. Only Qwen3-Omni was evaluated, so the result cannot rank all multimodal foundation models.
Clinical Use Should Start With Observable Flags, Not Autonomous Diagnosis
The deployment path suggested by these data is narrow. Observable domains may be useful as clinician-facing flags: speech pressured, affect restricted, psychomotor activity unusual, behavior changing over time. Even there, low specificity means false positives would need human review.
Inferential domains are not ready for unsupervised use. A system that misses hallucinations, delusions, or perceptual abnormalities because it cannot map narrative content into the correct MSE category is unsafe as a standalone psychiatric assessor.
- Lower-risk use: structured video review aids, longitudinal symptom flags, documentation prompts, and second-pass reminders for clinicians.
- Higher-risk use: autonomous MSE scoring, diagnostic triage, crisis assessment, or deciding that latent thought-content symptoms are absent.
- Research priority: benchmark multiple models against multi-center expert distributions, not one-panel answer keys.
Model compression adds another caution. The 4-bit quantized version dropped from 80.6% to 66.8% accuracy vs. Yale and shifted from calibrated aggregate prediction to marked over-prediction. Smaller, cheaper deployment may not preserve the reasoning behavior that matters most in psychiatric domains.
Questions About AI Mental Status Exams
Did Qwen3-Omni pass the mental status exam benchmark?
Not in a clinical-deployment sense. It reached moderate agreement with expert panels, but it stayed below expert-to-expert agreement and missed important inferential domains.
Why did the model miss perceptions and delusions?
The study suggests a reasoning failure more than a pure perception failure. The model could process speech but often failed to map subjective reports onto psychiatric categories.
Could this still help clinicians?
Possibly, as a review aid for observable signs or a prompt to check specific MSE domains. The evidence does not support autonomous psychiatric diagnosis, crisis triage, or unsupervised mental-status scoring.
References
- Mwangi B, Hamoudi HJAS, Sanches M, Dogan N, Chaudhary P, Wu MJ, Zunta-Soares GB, Soares JC, Martin A, Soutullo CA. Human vs AI clinical assessment: benchmarking a multimodal foundation model against multi-center expert judgment on the mental status examination. medRxiv. 2026. doi:10.64898/2026.04.17.26351105
- Martin A, Jacobs A, Krause R, Amsalem D. The mental status exam: an online teaching exercise using video-based depictions by simulated patients. MedEdPORTAL. 2020;16:10947. doi:10.15766/mep_2374-8265.10947
- Blaabjerg ES, Hemmingsen RPA, Hoegh E, Wang AG, Gefke M, Arnfred S. Variability between psychiatrists on domains of the mental status examination. Nordic Journal of Psychiatry. 2020;74:287-292. doi:10.1080/08039488.2019.1703038
- Liu Y, Xia S, Nie J, Wei P, Shu Z, Chang JA, Jiang X. aiMSE: toward an AI-based online mental status examination. IEEE Pervasive Computing. 2022;21:46-54. doi:10.1109/MPRV.2022.3172419
- Aykut A, Karayil AR, Yildirim C, Gunsoy E, Tatli M, Avci M. Multimodal large language model versus emergency physicians for burn assessment: a prospective non-inferiority study. Scandinavian Journal of Trauma, Resuscitation and Emergency Medicine. 2026;34. doi:10.1186/s13049-026-01577-6
- Goh E, Gallo R, Hom J, Strong E, Weng Y, Kerman H, Cool JA, Kanjee Z, Parsons AS, Ahuja N, Horvitz E, Yang D, Milstein A, Olson APJ, Rodman A, Chen JH. Large language model influence on diagnostic reasoning: a randomized clinical trial. JAMA Network Open. 2024;7:e2440969. doi:10.1001/jamanetworkopen.2024.40969