
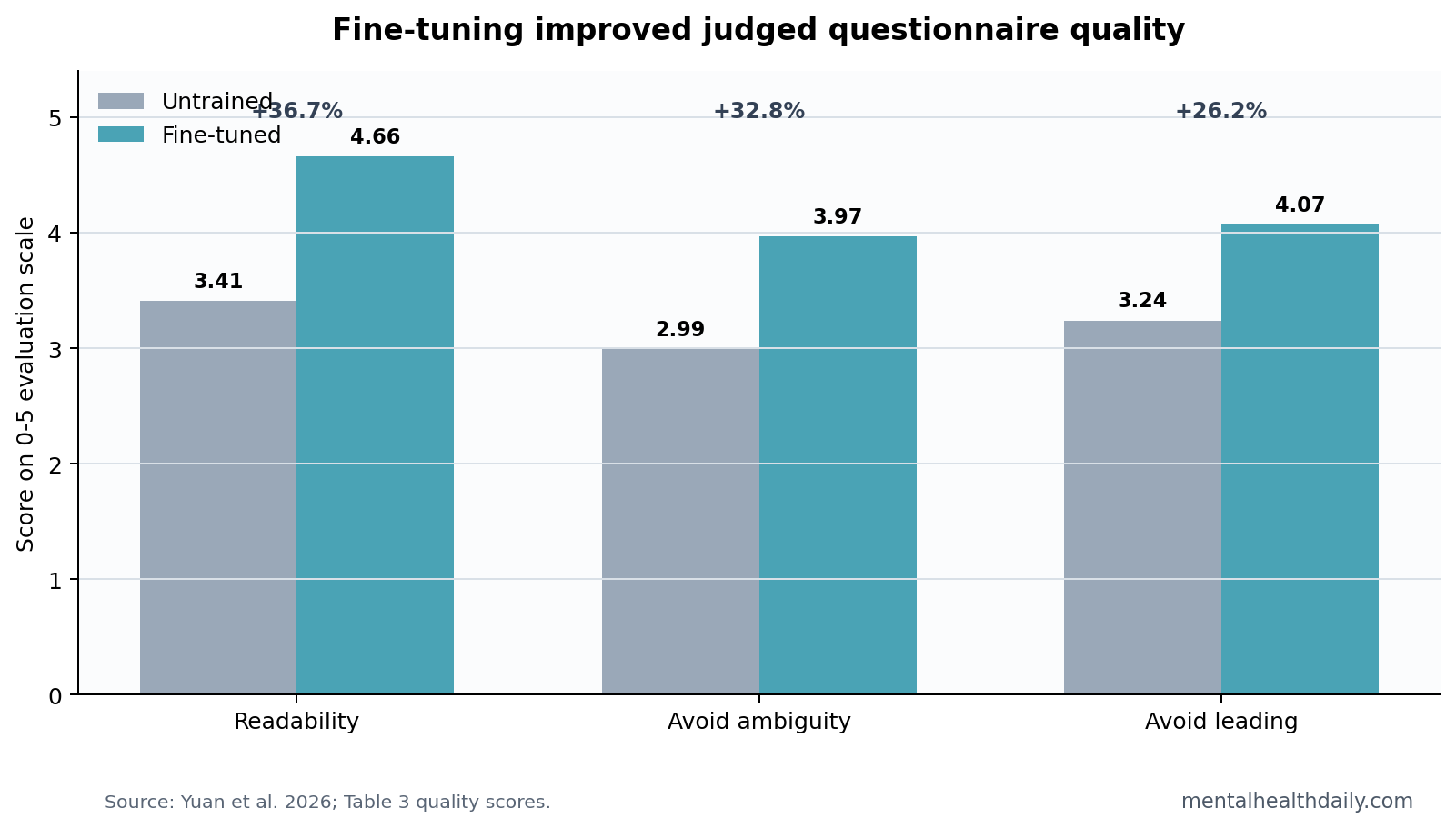
A 2026 PLOS One study fine-tuned Qwen-2.5 and GLM-4 for psychology questionnaire generation and reported the largest gain in readability and comprehension difficulty: 3.41 to 4.66 on a 0–5 scale, a 36.7% relative improvement.1 The result supports item drafting inside a psychometric workflow, while clinical or research scale use still requires ordinary validation.
Research Highlights
- Readability improved most: trained models scored 4.66 vs. 3.41 for untrained generation on readability and comprehension difficulty, a 36.7% relative gain.1
- Ambiguity still lagged: avoiding ambiguity improved from 2.99 to 3.97, but the study itself treated semantic ambiguity and cultural bias as unresolved psychometric risks.1
- The corpus was specialized: researchers screened 1,329 Chinese-language articles, selected 169 psychological questionnaires, excluded 8 hard-to-classify tools, and trained from 161 core instruments.1
- Expert agreement looked strong: 5 psychology experts rated 30 generated questionnaires, with Cohen’s kappa = 0.83 and small LLM-judge vs. expert gaps (MAE = 0.08; RMSE = 0.10).1
- Validation remains separate: rapid scale development can be valuable in emergencies, as COVID-19 scale work showed in 2020, but respondent-level reliability and validity still decide whether a questionnaire can be used.2
Large language model questionnaire generation means using an AI system to draft scale items, response options, or instructions for measuring a psychological construct. The model can produce plausible language quickly; psychometrics asks a harder question: whether those items measure the intended construct reliably, fairly, and reproducibly in real respondents.
Yuan et al. approached the problem as domain adaptation. The researchers collected public-health psychology questionnaires, fine-tuned 2 open-source models, and evaluated generated questionnaires with text-generation metrics plus expert-aligned quality scores.1
Fine-Tuned LLMs Made Questionnaire Items Clearer
The strongest result was not a claim about diagnosis or screening accuracy. It was a language-quality gain. On a 0–5 scoring system, trained generation improved from 3.41 to 4.66 for readability and comprehension difficulty, from 2.99 to 3.97 for avoiding ambiguity, and from 3.24 to 4.07 for avoiding suggestive guidance.1
Plain meaning: the fine-tuned models produced questionnaire text that judges rated as clearer, less leading, and better aligned with expert standards than untrained output. In measurement work, that is a real step because vague wording and leading items can contaminate every downstream analysis.
Text-generation metrics moved in the same direction. BLEU-4 increased from 0.18 at baseline to 0.22 for Qwen-2.5 and 0.21 for GLM-4. ROUGE-L increased from 0.54 to 0.58 for Qwen-2.5 and 0.56 for GLM-4. CIDEr increased from 0.39 to 0.46 for both fine-tuned models.1
A 191-Questionnaire Pool Anchored the Training Data
Training data quality is the load-bearing part of this study. Yuan et al. searched the Chinese-language China National Knowledge Infrastructure database through May 2024 and included 1,329 valid articles after duplicate removal.1
The study team then extracted psychological questionnaires mentioned in those articles and applied a 2-stage screen:
- Psychometric threshold: original publications needed reported psychometric support, such as Cronbach’s alpha ≥ 0.70.
- Expert review: 5 psychology experts assessed theoretical grounding, construct clarity, and fit for public-health psychology research.
- Corpus shape: 169 questionnaires survived the first selection, 8 were excluded because they were hard to classify, and 161 formed the core expert-validated corpus.
- Balanced sampling: 30 supplementary questionnaires were added from authoritative psychological platforms, creating a 191-questionnaire pool for sampling and feature learning.
Cronbach’s alpha is a reliability statistic that estimates whether items in a scale tend to move together as if they are measuring the same construct. It is not a complete validity test, but using alpha-supported instruments made the training corpus less arbitrary than scraping any questionnaire-like text from the web.
Expert Ratings Supported the Judge, Not Full Scale Validity
Yuan et al. used an LLM-as-judge method, meaning another model scored generated questionnaires across 7 dimensions: content relevance, language fluency, diversity and coverage, bias neutrality, readability, ambiguity avoidance, and avoidance of suggestive guidance.1
Because automated judging can become circular, the researchers added a human check. Thirty generated questionnaires, 15 from fine-tuned Qwen-2.5 and 15 from GLM-4, were rated by 5 psychology experts with at least 8 years of measurement experience. Human agreement was high, Cohen’s kappa = 0.83, and model-judge scores closely matched aggregated human scores, MAE = 0.08 and RMSE = 0.10.1
Calibration: that supports the credibility of the scoring method inside this study. It does not show that generated scales have stable factor structures, test-retest reliability, measurement invariance across groups, or predictive validity for clinical outcomes.
The distinction is especially important because the study’s strongest human check was a 30-questionnaire evaluation set, not a field test in patients, students, workers, or community respondents. Expert raters can judge whether generated items are readable and conceptually aligned, but they cannot show whether people interpret those items consistently under real survey conditions.
That makes the result useful earlier in the measurement pipeline. A research group could use a fine-tuned model to draft item variants, flag ambiguous wording, or compare translations before spending time on pilot testing. The same group would still need ordinary respondent data before treating the output as a scoreable instrument.
Emergency Measurement Is the Strongest Use Case
Psychological scale development can be slow. Yuan et al. framed the problem around the 3–6 month preparation cycle for traditional questionnaire development and noted the early COVID-19 problem: researchers needed instruments for fear of infection, lockdown anxiety, and social isolation before many validated tools existed.1
The COVID Stress Scales are a useful comparison. Taylor et al. developed and initially validated a COVID-specific distress measure in 2020, showing how fast measurement work can respond when a new public-health stressor appears.2 An LLM drafting system could make the early item-generation stage faster, especially when researchers need culturally adapted wording or variants for different populations.
Speed is not the same as readiness. A draft item bank can be produced quickly; a usable questionnaire still needs respondent testing. The practical role is earlier and narrower: generate candidate items, expose wording alternatives, and help experts iterate before formal validation starts.
LLMs Already Work Better for Text Analysis Than Scale Validation
Adjacent AI-psychology evidence is strongest when the task is language analysis, not full psychometric instrument creation. Rathje et al. reported that GPT could support multilingual psychological text analysis, which is closer to classification and interpretation of text than to creating a new measurement tool.3
Other health-assessment work has moved in the same direction. Wang et al. described LLM-enhanced health assessments as a methodological approach, and Ang et al. used AI-enabled content analysis to examine early maladaptive schemas in online mental-health communities.45
Those studies make the Yuan result more plausible: language models can help map psychological language. They also clarify the boundary. Text analysis, item drafting, and literature summarization are not the same as proving that a score should guide diagnosis, triage, treatment allocation, or public-health policy.
Psychometric Validity Still Has to Be Earned With Respondent Data
Psychometric validity means evidence that a questionnaire score actually reflects the intended construct and behaves properly across people, settings, and time. AI-generated wording can be fluent and still fail validity if items cluster around the wrong factor, disadvantage a subgroup, invite socially desirable answers, or respond differently across cultures.
Yuan et al. named several of those problems directly: semantic ambiguity, cultural bias, emotional sensitivity, privacy, ethics, and reverse-scored items.1 The reverse-scoring point is especially practical because many psychological scales include negatively worded items to control response bias. If an AI system gets polarity wrong, a scale can look coherent while scoring the opposite construct.
A serious validation pipeline would still need:
- Factor testing: whether items group into the intended dimensions.
- Reliability checks: internal consistency and test-retest stability.
- Measurement invariance: whether the scale behaves similarly across language, sex, age, culture, and clinical-status groups.
- Criterion validity: whether scores predict or align with clinically meaningful outcomes.
- Harm review: whether sensitive items create stigma, distress, privacy leakage, or biased classification.
Evidence-strength note: this was an LLM development and evaluation study, not a respondent-level clinical validation study. It supports AI-assisted questionnaire drafting inside a human psychometric workflow. It does not support using generated scales as standalone diagnostic or screening instruments.
The safe operational use is therefore constrained but real: let the model widen the candidate item pool, then let psychometric testing narrow it. Skipping that second step would convert a language-generation improvement into a false validity claim.
Questions About LLM-Generated Psychology Questionnaires
Did the fine-tuned models create validated psychological scales?
No. They improved generated questionnaire text and expert-rated quality scores. Validation of a real scale would still require respondent data, reliability testing, factor analysis, fairness checks, and outcome-linked validity evidence.
Why does readability matter for psychological questionnaires?
Confusing items add measurement noise. If respondents misunderstand the item, the score can reflect wording difficulty instead of anxiety, depression, risk perception, coping, or another intended construct.
Where could LLMs help most?
The best near-term use is candidate-item drafting, cultural wording adaptation, reverse-scoring checks, and expert review support. The final questionnaire still has to pass ordinary psychometric validation.
References
- Yuan Z, Jia C, Lan M, Zhao L, Chen Z, Yang M, et al. Research on the development of an automated system for psychology questionnaire generation based on large language models. PLOS One. 2026;21(4):e0345117. https://doi.org/10.1371/journal.pone.0345117
- Taylor S, Landry CA, Paluszek MM, Fergus TA, McKay D, Asmundson GJG. Development and initial validation of the COVID Stress Scales. Journal of Anxiety Disorders. 2020;72:102232. https://doi.org/10.1016/j.janxdis.2020.102232
- Rathje S, Mirea D-M, Sucholutsky I, Marjieh R, Robertson CE, Van Bavel JJ. GPT is an effective tool for multilingual psychological text analysis. Proceedings of the National Academy of Sciences. 2024;121(34):e2308950121. https://doi.org/10.1073/pnas.2308950121
- Wang X, Zhou Y, Zhou G. Enhancing health assessments with large language models: A methodological approach. Applied Psychology: Health and Well-Being. 2025;17(1):e12602. https://doi.org/10.1111/aphw.12602
- Ang BH, Gollapalli SD, Du M, Ng S-K. Unraveling online mental health through the lens of early maladaptive schemas: AI-enabled content analysis of online mental health communities. Journal of Medical Internet Research. 2025;27:e59524. https://doi.org/10.2196/59524