
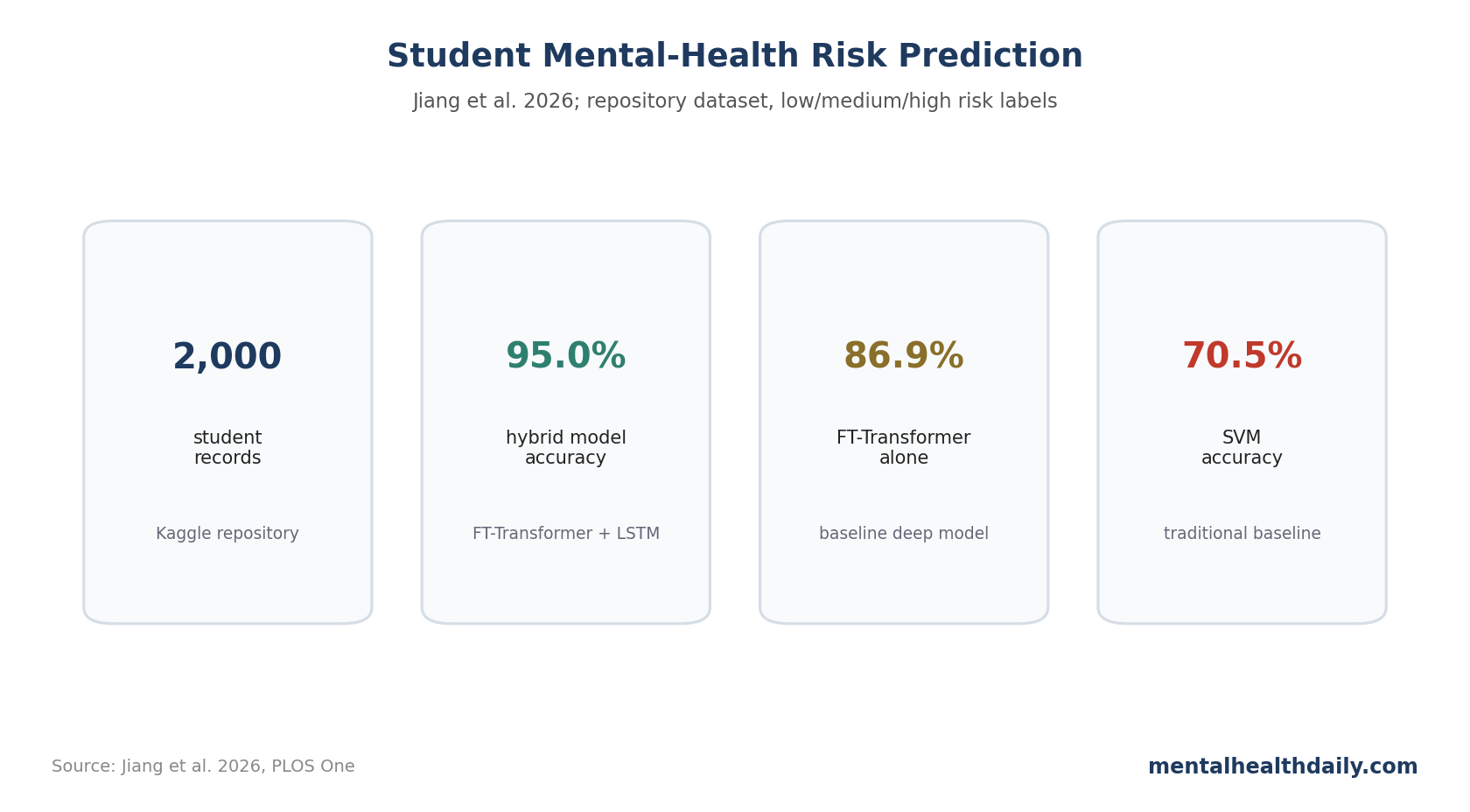
A 2026 PLOS One machine-learning study reported 95.0% accuracy for a hybrid FT-Transformer plus long short-term memory (LSTM) model predicting student mental-health risk. The technical result is strong inside the dataset, but the clinical claim is still limited because the labels came from repository data rather than prospective clinical diagnosis.1
Research Highlights
- 95.0% accuracy was reported: the proposed interpretable FT-Transformer + LSTM model reached 95.0% accuracy, 93.0% precision, 96.0% recall, and 95.0% F1-score.1
- Baselines were lower: support vector machine reached 70.5%, logistic regression 77.9%, random forest 79.2%, LSTM 84.0%, and FT-Transformer 86.9%.1
- The dataset was repository-based: 2,000 student records from Kaggle contained anxiety, depression, productivity, sleep, physical activity, social support, age, and demographic features.1
- Anxiety and depression dominated: feature-importance and LIME explanations weighted anxiety and depression scores most heavily, with productivity also important.1
- External validation is the missing test: a high score on 1 structured dataset still needs prospective validation, calibration, and bias audits before campus clinical use.
The model tries to combine performance with interpretability. It uses transformer-style feature attention, LSTM sequence modeling, and a cross-attention attribution layer (CAAL) that highlights feature interactions.
Mental-health AI papers can sound more clinically mature than their validation supports. The useful deployment test is whether the model still works when students, surveys, institutions, time, and clinical definitions change.
2,000 Student Records Were Split Into Low, Medium, and High Risk
Jiang et al. used a public Kaggle dataset with 2,000 student records and 10 psychological, behavioral, and demographic variables. Risk labels were created from normalized anxiety and depression values, with percentile-based segmentation into low, medium, and high risk.1
- Emotional features: anxiety score and depression score.
- Behavioral features: productivity score, sleep hours, physical activity days, stress level, and social support.
- Demographic features: age, gender, and employment status.
- Model target: low, medium, or high mental-health risk category.
If anxiety and depression scores help define the target, a model that relies heavily on anxiety and depression can perform well while still saying less about external clinical detection than the headline accuracy suggests.
FT-Transformer + LSTM Beat Conventional Models
The performance table showed a stepwise climb from simpler models to the hybrid architecture. AdaBoost reached 68.0% accuracy, support vector machine (SVM) 70.5%, logistic regression 77.9%, random forest 79.2%, LSTM 84.0%, FT-Transformer 86.9%, and the proposed hybrid 95.0%.1
Recall was especially high at 96.0%. Recall means the fraction of true high-risk cases that the model catches. In mental-health screening, false negatives can be more concerning than false positives if the system is meant to trigger voluntary support.
Anxiety, Depression, and Productivity Drove the Predictions
The feature-importance analysis ranked anxiety and depression as the dominant predictors, with contribution scores around 0.33 and 0.30. Productivity came next, while social support, sleep hours, and age were more moderate. Gender, employment, physical activity, and stress level had smaller direct importance in the reported model.1
Local Interpretable Model-Agnostic Explanations (LIME) pointed in the same direction. For a representative high-risk case, high depression scores above 23 and anxiety scores above 11 pushed the model toward high risk, while productivity affected the prediction in the expected direction.1
The model’s logic is psychologically plausible, but it may also be partly rediscovering the scoring rules embedded in the labels.
Model Explanations Still Need Prospective Campus Testing
Explainable AI tools help clinicians and researchers inspect model behavior. They do not automatically solve validity, fairness, consent, or deployment risk.2
- Dataset shift: a Kaggle dataset may not resemble a real university counseling population.
- Label circularity: if anxiety and depression scores help define the target, high feature importance for anxiety and depression is partly expected.
- Clinical calibration: probability outputs need to match real-world risk, with class labels treated as only 1 layer of validation.
- Bias testing: performance must be checked across gender, age, socioeconomic status, disability, language, and institution type.
- Actionability: a risk score is only useful if it connects to voluntary, humane support.
Campus AI Should Optimize Triage, Not Replace Human Judgment
The realistic use case is triage support. A model might help identify which voluntary screening responses should trigger a faster check-in, which students might benefit from self-guided resources, or which risk profiles deserve human review.
It should not decide who is mentally ill, who is unsafe, or who loses privileges. The stakes of false positives and false negatives are too high, and student trust collapses quickly when screening feels disciplinary.
Prospective validation should be designed like a clinical screening study. The model should be tested on new students, across multiple campuses, with predefined thresholds, calibration curves, and subgroup performance. It should report sensitivity and specificity at practical decision points, with overall accuracy treated as a starting metric.
Data governance: students need to know what features are used, who can see the output, how long data are retained, and whether opting out changes access to services. A technically good model can still be a bad campus tool if governance is vague.
- Follow-up capacity: high recall helps only if counseling teams can respond to the extra alerts.
- Clinical baseline: the deep model should beat simple PHQ/GAD-style rules as well as other machine-learning models.
- Student control: predictions should stay opt-in and visible to the student whenever possible.
The model is best read as an engineering proof-of-concept. Its next test is whether it generalizes outside the dataset and whether it can be embedded in a support system students would actually trust.
High Recall Is Useful Only if Follow-Up Capacity Exists
The reported 96.0% recall sounds attractive because missed high-risk cases are dangerous. But high recall can increase the number of students flagged, especially when prevalence is high or thresholds are low.
A campus system needs to know whether counseling services can respond. If the model identifies many students as high risk but the school has no rapid, voluntary, supportive follow-up, the tool may create anxiety without care.
False positives also need a humane pathway. A student should not be treated as deceptive, unstable, or administratively risky because a model assigned a probability. The first response should be an offer: resources, check-in, appointment availability, crisis information, and privacy-respecting choice.
Good validation reports should therefore include workload metrics: how many alerts per 1,000 students, how many true high-risk cases caught, how many students contacted, how many accepted help, and whether outcomes improved.
Feature Importance Should Be Audited for Clinical Redundancy
The model’s strongest features were anxiety and depression scores. The weighting is clinically plausible, but it also raises a redundancy question: if a short anxiety and depression screen already identifies risk, how much extra value does the complex model add?
The right comparison includes SVM, random forest, and a simple clinical rule, such as PHQ/GAD thresholds plus impairment, social support, and sleep. If the deep model does not improve decision-making beyond transparent rules, simpler screening may be better.
Model Reporting Should Include Threshold-Specific Tradeoffs
Overall accuracy hides the decision threshold. A high threshold may reduce false positives but miss distressed students. A low threshold may catch more high-risk students but overload counseling services.
Future reports should show confusion matrices, calibration plots, decision curves, and alert volume at several thresholds. A campus does not deploy an AUC; it deploys a rule that decides when someone is contacted.
Privacy Risk Scales With Institutional Power
Mental-health prediction is different from predicting course completion or library demand. A risk label can affect self-image, trust, academic relationships, and willingness to seek help. The more institutional power sits behind the model, the higher the privacy bar should be.
The safest deployment would keep predictions under student control whenever possible: personal dashboards, opt-in sharing, and voluntary referral. Administrative access should be minimized and audited, with clear rules against disciplinary or academic use.
Transparency is not the same as consent. LIME plots and feature weights can explain why a model classified a record, but they do not answer whether students agreed to that use of their data. A campus system would need plain-language consent, visible data retention rules, and a way to receive support without being forced into automated risk scoring.
Clinical usefulness depends on comparison. A student-health service should benchmark the hybrid model against short validated questionnaires, counselor triage, crisis-line protocols, and simple sleep or support flags that are easier to explain.
Questions About AI Student Mental-Health Screening
Is 95% accuracy enough for campus use?
No. It is enough to justify validation in new data. Campus use would require prospective testing, privacy safeguards, calibration, and a support protocol.
Why mention the label problem?
If risk labels are derived from anxiety and depression values, a model can look excellent by learning those same variables. That can still be useful engineering, but it is not the same as predicting clinician-diagnosed risk.
Could this kind of model help?
Potentially. The safest use is decision support for voluntary screening and resource allocation, not automated labeling of students.
References
- Predicting student mental health through entropy-based features and interpretable cross-attention transformer networks. Jiang et al. doi:10.1371/journal.pone.0347294
- Why Should I Trust You? Explaining the Predictions of Any Classifier. Ribeiro et al. doi:10.1145/2939672.2939778
- Revisiting Deep Learning Models for Tabular Data. Gorishniy et al. doi:10.48550/arxiv.2106.11959
- Machine learning for student mental-health screening. PubMed search. PubMed search